<1장 : 쿠버네티스 소개>
1.1 쿠버네티스 시스템이 필요한 이유
- 모놀리식 애플리케이션
- 마이크로서비스로 애플리케이션 분리
- 애플리케이션에 일관된 환경을 제공할 필요성
1.2 컨테이너 기술 소개
- 리눅스 컨테이너 기술을 통한 컴포넌트의 분리
- 도커
1.3 쿠버네티스 소개
- 쿠버네티스: 컨테이너 애플리케이션을 쉽게 배포하고 관리할 수 있게 해주는 소프트웨어 시스템
- 애플리케이션을 컨테이너별로 격리하면서 하드웨어를 최대한 활용 가능하게 한다.
- 쿠버네티스 시스템은 마스터 노드와 여러 개의 워커 노드로 구성된다.
- 개발자가 애플리케이션 매니페스트를 마스터에 제출하면 쿠버네티스가 이것을 워커 노드 클러스터에 배포하고 리소스를 할당해 실행한다. 어떤 노드에서 해당 애플리케이션이 실행되는지는 개발자가 신경쓰지 않아도 된다.
- 쿠버네티스는 서비스 검색, 확장, 로드 밸런싱, 자가 치유, 리더 선출 같은 서비스들을 제공하고, 이는 개발자가 인프라보다 실제 기능에 집중할 수 있게 한다.
- 마스터 노드(컨트롤 플레인): 클러스터 관리, 기능 실행. 다음 요소들로 구성된다.
- 워커 노드: 컨테이너화된 애플리케이션 실행. 다음 요소들로 구성된다.
- 쿠버네티스에서의 애플리케이션 실행
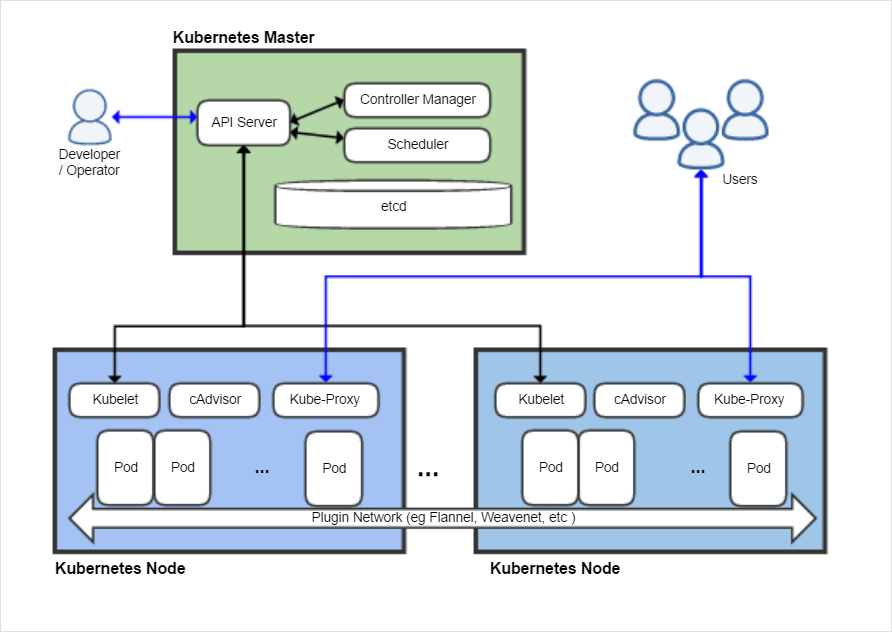
- 사용자는 컨테이너 이미지들을 패키지로 만들어 레지스트리에 푸시한 후 API 서버에 애플리케이션 디스크립션을 게시한다.
- 스케줄러는 API서버가 애플리케이션의 디스크립션을 처리할 때 필요한 리소스를 기반으로 워커 노드를 예약한다.
- Kubelet은 이미지 레지스트리(etcd)에서 컨테이너 이미지를 가져와 컨테이너를 실행하도록 도커에 알린다.
- 실행중인 컨테이너 유지: 애플리케이션이 실행되면 쿠버네티스는 사용자가 지정한 배포 상태를 유지한다.
- 복제본 수 확장: 애플리케이션이 실행되는 동안 복사본의 수를 조절할 수 있다.
- 이동 중인 대상에 접근: kube-proxy가 서비스를 제공하는 컨테이너들의 서비스 연결 부하를 분산하여 클라이언트가 항상 해당 컨테이너에 접근할 수 있도록 한다.
- 쿠버네티스의 장점
<2장 : 도커와 쿠버네티스의 첫걸음>
2.1 컨테이너 이미지의 생성, 실행, 공유
- 도커(Docker)를 이용하여 컨테이너 이미지 패키징, 공유, 실행할 수 있다
- docker run 명령을 이용하여 실행할 이미지를 지정하고, 실행할 명령을 지정할 수 있다. 이미지가 없는 경우 자동으로 이미지를 다운로드한다. 이미지는 hub.docker.com 등 공개 레지스트리에서 사용할 수 있는 이미지를 검색한다
$ docker run busybox echo “Hello world” // busybox 이미지를 실행하고 echo “Hello world” 실행 명령
- 실행할 명령 (ex : echo “Hello world”) 를 이미지 자체에 구울수도 있다
- 동일한 이미지에 대해 여러 버전이 있을 수 있는데, 이를 태그로 구분한다. 태그를 지정하여 이미지를 수행할 수 있고, 지정을 안하면 최신버전을 가정한다
$ docker run <image>:<tag>
- 컨테이너 내부에서 실행중인 앱은 자체 호스트 이름을 보며, 호스트 시스템의 다른 앱은 볼 수 없다
- 앱을 이미지에 패키징하려면 Dockerfile 을 만들고 해당 파일에 도커가 이미지를 빌드할 때 수행할 지시사항을 기록한다.
FROM node:7 // FROM : 빌드 기본 이미지로 사용할 컨테이너 이미지
ADD app.js /app.js // ADD : 이미지의 루트 디렉터리에 app.js 로 파일 추가
ENTRYPOINT [“node”, “app,js”] // 이미지를 실행할 떄 수행할 명령 (node app.js)
- 도커파일과 빌드할 파일을 준비한 후, docker build 명령으로 이미지를 만들 수 있다
$ docker build -t kubia .
- 빌드는 도커 클라이언트가 아닌 도커 데몬에서 빌드되며 데몬과 클라이언트는 별도 머신에 존재할 수 있다
- 이미지는 여러개의 레이어로 구성되며, 각 레이어별로 이미지 pull 과정이 있다. 도커파일의 각 명령에 대해 새 레이어가 만들어진다. 레이어는 다른 이미지와 공유될 수 있으므로 효율적이다. docker images 명령으로 로컬에 저장된 이미지들을 확인할 수 있다
- 컨테이너에서 명령을 실행, 종료한 후 최종 상태를 새 이미지로 커밋할 수 있다
- 도커 실행시 옵션으로 추가정보를 제공할 수 있다
$ docker run --name kubia-container -p 8080:8080 -d kubia
--name : 컨테이너 이름 지정
-p : 컨테이너 내부의 포트 8080을 로컬 컴퓨터의 8080으로 매핑한다
-d : 컨테이너가 콘솔에서 분리되어 백그라운드로 작동한다
- docker inspect <컨테이너명> 으로 컨테이너의 자세한 정보를 JSON 형식으로 확인할 수 있다
- docker exec을 이용하여 실행중인 컨테이너 내부에서 추가 프로세스를 실행할 수 있다
$ docker exec -it kubia-container bash
-i : STDIN을 오픈 상태로 유지하고 셸에 명령을 입려할 때 필요
-t : 의사터미널(tty)를 할당한다
- 컨테이너 내부에서는 호스트의 다른 앱을 볼 수 없고, 호스트 os에서는 확인 가능하다. 컨테이너는 자체 PID 리눅스 네임스페이스를 가지고 있어 PID가 다르게 나타난다
- 각 컨테이너는 격리된 파일 시스템을 가지고 있다
- docker stop 명령으로 컨테이너를 중지할 수 있고, 이 때 컨테이너 자체는 여전히 존재하고 컨테이너에서 실행중인 기본 프로세스가 중지된다
- docker rm 명령으로 컨테이너를 삭제하고, 모든 내용이 제거되면 다시 시작할 수 없다
- docker tag로 이미지의 이름을 바꿀 수 있다. 같은 이미지에 태그가 추가될 수 있다. (alias개념처럼)
- docker push를 이용하여 이미지를 레지스트리에 푸시할 수 있다
2.2 쿠버네티스 클러스터 설정
- 클러스터 설정 후, 이미지를 도커에서 직접 실행하는 대신 쿠버네티스 클러스터에 배포할 수 있다.
- 쿠버네티스 클러스터 내에서 모든 컨테이너가 동일한 네트워크 공간에서 서로 연결될 수 있어야 한다
- 다양한 환경 (로컬 개발장비, 컴퓨터 클러스터, 가상머신 제공 클라우드 등등) 에서 쿠버네티스 클러스터를 구성할 수 있으며, 책에서 제시하는 방법으로는 미니큐브(minikube) 를 이용하여 로컬에서 단일 노드 클러스터를 구성할 수 있으며. 구글 쿠버네티스 엔진(GKE) 를 이용하여 클러스터를 호스트받고 그 위에 구성할 수도 있다.
- 쿠버네티스를 다루려면 kubectl CLI 클라이언트가 필요하다
- $ kubectl cluster-info 를 수행하여 클러스터가 작동중인지 확인할 수 있다
- GKE를 이용하면 여러 노드의 클러스터 환경을 손쉽게 생성할 수 있다
- 마스터노드에는 쿠버네티스 API 서버가 존재하고, 워커 노드에서는 도커, Kubelet, kube-proxy 를 수행한다.
- 사용자가 kubectl 을 이용해 명령을 수행하면 REST 요청이 마스터 API로 전달되는 방식으로 클러스터와 상호작용한다
- $ kubectl get nodes 명령어로 클러스터를 구성하는 노드들을 확인할 수 있다
- $ kubectl describe 명령을 사용하여 쿠버네티스 객체의 정보를 상세하게 알 수 있다
$ kubectl describe node gke-kubia-85f6 // 지정 노드의 상태, CPU/메모리 데이터, 실행 컨테이너 등 정보들을 출력한다. 노드명을 입력하지 않으면 모든 노드 정보를 출력한다
2.3 쿠버네티스에서 첫번째 앱 실행
- 일반적으로는 쿠버네티스 환경에서 앱 배포를 위해 JSON 이나 YAML 매니페스트를 준비해야 하지만, 간단하게 kubectl 명령을 이용해서도 앱을 실행할 수 있다
- kubectl run 명령을 이용하여 쿠버네티스에서 이미지를 수행할 수 있다
$ kubectl run kubia --image=luksa/kubia --port=8080 --generator=run/v1
--image : 실행하려는 컨테이너 이미지 명시
--port : 앱이 해당 포트에서 수신대기중임을 알려준다
--generator : 일반적으로 사용하지 않는 옵션. 사용하는 리소스와 관련된 버전 정보를 표기한다.
- 쿠버네티스는 개별 컨테이너를 취급하는 대신 포드(Pod) 라는 컨테이너 그룹을 단위로 관리한다
- 포드는 하나 이상의 관련 컨테이너 그룹을 의미하며, 한 포드 내의 컨테이너들은 동일 리눅스 네임스페이스와 동일 워커 노드에서 항상 함께 실행된다
- 포드는 자체 IP, 호스트이름, 프로세스 등이 있는 별도의 논리적 시스템이다
- $ kubectl get pods 명령을 이용하여 포드들을 나열할 수 있다. 포드가 이미지를 다운로드 중인 동안에는 시작되지 않고 Pending 상태로 존재한다. 다운로드를 마치고 실행되면 Running 상태가 된다
- kubectl 명령이 수행되고 나면 우선 REST 에 의해 마스터가 포드 생성을 명령받고, 스케줄링하여 워커 노드 중 하나에 통지한다. 워커의 Kubelet 에서 통지를 받으면, kubelet이 도커에게 이미지를 실행하도록 명령하여 도커가 (이미지가 없으면 다운로도하고) 이미지를 실행한다
- 포드 객체를 실제로 생성하는 것은 kubectl run 명령을 통해 생성된 레플리케이션 컨트롤러이다. 레플리케이션 컨트롤러는 설정에 따라 포드를 지정된 개수만큼 복제한다. 어떤 이유로든 포드의 개수가 설정과 맞지 않으면 레플리케이션 컨트롤러가 이를 만족시킬 때 까지 포드를 추가 생성하거나 삭제한다
- 포드에는 자체 IP가 있지만 이는 클러스터 내부에서만 접근 가능하므로, 외부에서 앱을 액세스할 수 있게 하려면 서비스 객체를 만들어 IP를 노출해야 한다
- ClusterIP 서비스는 클러스터 내부에서만 액세스 할 수 있으므로 LoadBalancer 형태의 특별한 서비스를 만들어 로드밸런서의 공용 IP를 통해 외부에서 포드에 연결할 수 있다
- kubectl expose 명령을 이용하여 서비스 객체를 생성하고 위에서 작성한 레플리케이션 컨트롤러를 노출할 수 있다
$ kubectl expose rc kubia --type=LoadBalancer --name kubia-http
rc : replication controller의 alias
- $ kubectl get services 명령으로 서비스에서 제공하는 외부 IP와 포트를 확인할 수 있다
- 레플리케이션 컨트롤러에 의해 포드가 중간에 삭제되거나 추가될 수 있는데, 이 때문에 포드상에 존재하는 앱의 접속 IP 주소가 계속 바뀔 수 있다. 외부에서는 단일 주소로 앱에 계속 접속할 수 있어야 하기 떄문에 이 기능을 제공하기 위해 서비스가 존재한다
- 쿠버네티스를 이용하면 편하게 배포를 확장할 수 있다.
- 레플리케이션 컨트롤러에서 포드의 원하는 레플리카 수를 결정하여 복제본 수를 증가시킬 수 있다. kubectl scale 명령을 사용한다
$ kubectl scale rc kubia --replicas=3 // 포드가 항상 3개 인스턴스를 유지해야 한다고 명령
- 쿠버네티스의 기본 원칙은 원하는 상태를 선언적으로 변경하는 것이다. 쿠버네티스는 실제 상태를 검토하여 선언한 원하는 상태로 조정한다
- 쿠버네티스의 수평적 확장 기능을 이용하기 위해, 앱 자체가 수평적으로 확장될 수 있어야 한다
- kubectl get pods 수행시 -o wide 옵션을 이용하여 해당 포드가 어떤 노드에 스케줄링되었는지 확인할 수 있다
$ kubectl get pods -o wide
- describe 명령으로도 포드의 세부 내용을 확인하면서 어떤 노드에서 수행중인지 확인할 수 있다
- 쿠버네티스 상태를 편하게 확인할 수 있는 웹 대시보드를 제공한다
<3장 : 포드: 쿠버네티스에서 컨테이너 실행하기>
3.1 포드 소개
- 포드는 쿠버네티스의 기본 빌딩 블록을 대표하는 것으로 컨테이너를 포함한다.
- 각각의 프로세스에 대해 관리의 편리를 위해 각각의 컨테이너로 구성하는 것을 지향하며, 이러한 컨테이너를 단일 단위로 관리하기 위한 상위 레벨 구조로 포드를 사용한다.
- 포드의 모든 컨테이너는 동일한 네트워크 및 UST 네임스페이스에서 실행되기 때문에 모두 같은 호스트 이름 및 네트워크 인터페이스를 공유한다.
- 포드는 논리 호스트이며 물리적 호스트 또는 컨테이너가 아닌 환경에서 가상머신과 유사하게 작동한다.
- 하지만 꼭 하나의 프로세스에 대해 하나의 포드에 하나의 컨테이너만 있는 것이 아니며, 프론트엔드와 백엔드와 같은 경우 다수의 포드로 분할하여 하나의 노드에서 프론트엔드 다른 노드에서 백엔드를 스케쥴링 할 경우 활용도가 높다.
- 또한 일반적으로 포드의 기본 컨테이너는 웹 서버이며 추가 컨테이너의 경우 사이드카 컨테이너의 경우 하나의 포드에 다수의 컨테이너를 사용한다. 사이드카 컨테이너(원래 사용하려고 했던 기본 컨테이너의 기능을 확장하거나 강화하는 용도의 컨테이너 추가 패턴)의 종류에는 로그 로테이션, 수집장치, 데이터 프로세서, 통신 어댑터 등이 있다.
3.2 YAML이나 JSON 파일 디스크립터에서 포드 만들기
- 포드와 쿠버네티스 리소스는 JSON 또는 YAML 매니페스트를 쿠버네티스 REST API 엔드포인트에 게시해 생성한다.
- $ kubectl get po pod 이름 -o yaml를 통하여 포드의 정의를 살펴보면 몇가지의 부분으로 구성된다.
- meta data에는 포드 이름, 네임스페이스 라벨, 그밖의 정보가 있다.
- spec에는 포드의 컨테이너, 볼륨, 그 밖의 데이터와 같은 포드 내용의 실제 설명이 있다.
- status에는 포드의 상태, 각 컨테이너의 설명 및 상태, 포드 내부의 IP 및 그밖의 기본 정보등 실행중인 포드의 현재 정보가 있다.
- YAML 디스크립터를 $ kubectl create -f ~~.yaml 를 통하여 포드를 쉽고 간편하게 생성할 수 있으며, 포트를 명시적으로 정의하면 각 포트에 이름을 할당할 수 있어 유용하다. 또한 $ kubectl explain pods 를 통하여 포드에 대한 설명을 요청할수 있다.
- $ docker logs <container id> 을 통하여 포드가 실행 중인 노드에 로그인하여 로그를 검색할수 있으나 쿠버네테스의 경우 $ kubectl logs 포드이름 을 통하여 쉽게 포드의 로그를 가져올 수 있다.
- $ kubectl port-forwad 포드이름 8888(로컬포트):8080(포드포트) 를 통하여 특정 포드와 서비스를 거치지 않고 통신을 할 수 있으며 이를 통해 실제 포드의 동작을 볼 수 있다.
3.3 라벨을 이용한 포드 구성
- 라벨은 포드뿐만 아니라 쿠버네티스의 모든 리소스를 구성하는 기능으로 키/값을 통하여 많은 수의 포드를 쉽게 탐색 및 조회를 가능하게 한다.
- 라벨을 있는 포드를 생성할 경우 $ kubectl get po --show-labels 를 통하여 라벨에 대한 내용을 볼 수 있으며, -L label key 옵션을 통하여 원하는 라벨에 대해서 포드를 조회할 수 있다.
- $ kubectl label po 포드이름 label key = value를 통하여 라벨을 수정할 수 있으며 기존의 라벨을 변경할 경우 --overwrite 를 통하여 오버라이트를 해야한다.
3.4 라벨 셀렉터를 통한 하위 집합 나열하기을 이용한 포드 구성
- $ kubectl get op -I label key = value를 통하여 label의 value를 통한 포드 나열이 가능하다.
- 라벨 셀렉터에 대한 다양한 옵션이 가능핟.
- !A : A 이외의 다른 값으로 라벨이 있는 포드 선택
- A in(b,c) : A 라벨이 b 또는 c로 설정된 포드 선택
- A notin(b,c) : A 라벨이 b 또는 c이 아닌 다른 값으로 설정된 포드 선택
- 다중 조건에 대한 라벨 셀렉터가 가능하다.
3.5 포드 스케줄링 제약을 위한 라벨과 셀렉터의 사용
- 포드뿐만 아니라 노드에 대해서도 셀렉터를 통하여 워커 노드를 분류할수 있다.
- $ kubectl label node 노드 이름 gpu = true와 같이 GPU 컴퓨팅에 사용되는 노드에 대해서 라벨을 붙일수 있다.
- 이러한 노드에 대해서 포드를 스케쥴링 하려고 할 경우 포드의 YAML에 (nodeSelector : gpu : “true”) 노드 셀렉터를 추가하여 노드에 대한 포드를 스케쥴링 할수 있다.
3.6 포드에 주석 달기
- 라벨 외에도 포드와 그 밖의 객체에 주석(annotation)을 넣을 수 있다. 주석은 키/값 쌍으로 라벨과 비슷하지만 식별 정보를 포함하지는 않는다. 따라서 라벨을 사용할 수 있는 방식으로 객체를 그룹화 하는데 사용할 수 없다.
- 따라서 주석은 주로 도구에서 사용하며, 각 포드나 API 객체 설명이 추가되므로 클러스터를 사용하는 모든 사람이 각 객체의 정보를 빠르게 찾을 수 있다.
- 주석의 추가의 경우 $ kubectl annotate pod 포드 이름 mycompany,com/someannotaion=”foo bar”(주석 내용) 의 추가의 형태로 주석을 추가하며, $ kubectl describe pod 포드 이름을 통하여 추가한 주석을 볼 수 있다.
3.7 그룹 리소스의 네임 스페이스 사용하기
- 객체를 서로 겹치지 않는 별개의 그룹으로 분리하는 경우에는 네임스페이스로 그룹화한다.
- 쿠버네티스의 네임 스페이스는 서로 프로세스를 격리시키는 데 사용이 되고, 단일 네임스페이스 하나에 모든 리소스를 갖는 대신 여러 개의 네임스페이스로 분할할 수 있으므로 동일한 리소스 이름을 여러 네임스페이스에서 여러 번 사용할 수 있다.
- YAML 파일을 통하여 $ kubectl create namespace YAML파일 네임스페이스를 생성할 수 있고, $ kubectl create -f 포드생성.yaml 네임스페이스YAML파일 을 통하여 포드에 대해 네임스페이스를 지정하여 객체를 관리할 수 있다.
- 네임스페이스를 사용하면 객체를 별개의 그룹으로 격리할 수 있지만 지정된 네임스페이스에 속한 객체만 조작할 수 있으므로 실행 중인 객체를 격리하지 않는다.
3.7 포드의 중지와 삭제
- $ kubectl delete po 포드 이름으로 포드를 삭제한다.
- $ kubectl delete po -I 라벨 key = value 방법을 통하여 원하는 라벨의 value에 대해 라벨 셀렉터로 포드를 삭제한다.
- $ kubectl delete ns 네임스페이스 이름 방법을 통하여 네임스페이스를 이용하여 포드를 삭제한다.
- 또한 --all 옵션을 사용하여 현재 네임스페이스의 모든 포드를 삭제한다.
<4장 : 레플리케이션과 그 밖의 컨트롤러: 포드 배포 관리>
- 배포한 애플리케이션의 상태 관리를 위해, 레플리케이션컨트롤러 또는 디플로이먼트와 같은 유형의 리소스를 생성한다.
4.1 포드를 안정적으로 유지하기
- 포드에서 실행되는 애플리케이션에 버그가 발생하면 쿠버네티스가 자동으로 다시 시작하지만, hang이 걸린 상황은 캐치하지 못한다.
- 라이브니스 프로브: 컨테이너에 라이브니스 프로브를 지정하여 포드를 주기적으로 검사할 수 있다. 세 가지 메커니즘을 이용하게 되는데,
- 라이브니스 프로브에 대한 정의는 포드의 YAML에 할 수 있으며, delay, timeout, period 등과 같은 추가 속성 지정도 가능하다.
- 효과적인 라이브니스 프로브는
4.2 레플리케이션 컨트롤러 소개
- 라이브니스 프로브를 이용하더라도 노드 자체에 문제가 생긴 경우는 복구가 불가능하다. 다른 노드에서 애플리케이션이 뜨도록 하기 위해 레플리케이션 컨트롤러 또는 유사한 메커니즘이 필요하다.
- 레플리케이션컨트롤러는 실행 중인 포드를 모니터링하고, 실제로 원하는 수 만큼의 포드가 떠 있는지를 항상 확인한다.
- 세 가지 요소로 구성된다.
- 다른 리소스와 동일하게 YAML 파일을 게시하여 생성 가능하다. 만약 수동으로 포드를 삭제하면, 바로 레플리케이션컨트롤러가 새 포드를 즉시 스핀업 해 복제본 수에 해당하는 만큼 포드가 떠있도록 한다. 컨트롤러는 포드의 삭제 같은 동작과 상관없이 현재 상태를 확인하여 YAML에 정의된 바와 다를 경우 상태를 맞춘다.
- 컨트롤러를 통해 스케일링을 해야 한다면, replicas(복제본 수)의 숫자만 변경하면 된다.
- 컨트롤러를 삭제하면 관리되던 포드도 삭제된다. 하지만 삭제 시에 --cascade=false 옵션을 통해 포드가 관리되지 않는 상태로 떠있도록 하는 것도 가능하다.
4.3 레플리케이션컨트롤러 대신 레플리카셋 사용
- 차세대 레플리케이션컨트롤러, 완전히 레플리케이션컨트롤러를 대체할 수 있다.
- 레플리케이션컨트롤러와 거의 비슷하게 동작하지만 포드 셀렉터를 좀 더 많은 방식으로 표현 가능하다: 특정 라벨이 없거나 특정 라벨을 포함하는 포드를 선택할 수 있는데, 다음 네 가지 연산자를 이용할 수 있다.
4.4 데몬셋으로 각 노드에 정확히 한 개의 포드 실행하기
- 클러스터의 각 노드에서 포드를 실행해야 하는 경우에 사용한다.
- 데몬셋은 노드가 있는 수만큼 포드를 생성하고 각 노드에 포드를 하나씩 배포한다. 노드가 다운돼도 포드를 생성하지 않지만, 노드가 추가되면 데몬셋은 새 포드 인스턴스를 생성해 즉시 배포한다.
- 레플리카셋과 마찬가지로 구성된 포드 템플릿으로부터 포드를 생성한다.
- 데몬셋 정의 내의 포드 템플릿에서 node-Selector 속성을 지정하여 특정 노드에만 포드를 배포할 수 있다. 포드가 필요한/필요하지 않은 노드에도 동일한 속성의 라벨을 지정해야 한다.
4.5 완료 가능한 단일 태스크를 수행하는 포드 실행
- 잡(job): 어떤 태스크가 완료되고 나서 다시 시작되지 않는 포드를 실행할 수 있다. 예를 들어 데이터를 저장하고 내보내는 것과 같은 임시 작업에 유용하다.
- 잡 또한 YAML을 이용해 선언된다. 잡은 무제한 실행되지 않으므로 restartPolicy의 default값인 Alway를 사용할 수 없고, OnFailure 또는 Never로 명시가 되어야 한다.
- 잡은 또한 두 개 이상의 포드 인스턴트를 병력적/순차적으로 실행하도록 구성할 수 있다. 이것은 실행 중에도 변경 가능하다.
- activeDeadlineSeconds 속성을 설정해 일정 시간이 지나면 포드를 종료하고 잡을 실패한 것으로 간주하도록 설정할 수 있다.
4.6 잡을 주기적으로 또는 한 번만 실행하도록 스케줄링
- CronJob 리소스를 작성해 잡을 예약할 수 있다.
- CronJob 리소스에는 생성될 잡 리소스의 템플릿이 명시되고, 언제 마다 그 잡을 실행할 것인지에 대한 스케줄 구성 정보도 적힌다.
<5장 : 서비스: 클라이언트가 포드를 검색하고 통신을 가능하게 함>
5.1 서비스 소개
- 서비스: 동일한 서비스를 제공하는 포드 그룹에 단일 진입 점을 만들기 위해 생성하는 리소스
- 서비스의 IP와 포트는 서비스가 존재하는 동안 변경되지 않는다. 따라서 프론트엔드 포드가 환경 변수 혹은 DNS를 통해 이름으로 백엔드 서비스를 찾는 것이 가능해 진다.
- 서비스 생성은 레플리케이션컨트롤러 등과 마찬가지로 kubectl expose를 사용하거나, YAML 디스크립터 생성을 통해 이루어질 수 있다. YAML에 서비스가 사용할 포트(A)와 포워드할 컨테이너 포트(B) 및 라벨 셀렉터를 명시하면, A로 들어오는 연결을 허용해 라벨 셀렉터에 매칭되는 포드 중 하나를 B 포트로 라우팅한다.
- 서비스를 통해 명령을 전달하면 서비스 프록시에 의해 랜덤하게 선택된 포드로 리다이렉션이 이루어진다. 하지만 sessionAffinity 속성을 ClientIP로 설정하면 서비스 프록시는 같은 클라이언트 IP로부터 발생한 요청을 항상 같은 포드로 리다이렉트한다.
- 서비스는 두 개 이상의 포트를 리다이렉션할 수 있고, 포트의 이름도 지정할 수 있다.
- 클라이언트는 환경 변수를 통해 실행 중인 서비스의 접속 정보를 알아낼 수 있고, DNS서버를 통해 서비스를 검색할 수 있으며, FQDN 사용을 통해 서비스를 연결할 수도 있다.
5.2 클러스터 외부 서비스에 연결
- 서비스가 클러스터 내의 포드 대신 외부의 IP와 포트로 연결을 리다이렉트해야 하는 경우도 존재한다.
- 포드에 대한 연결을 리다이렉트 할 때, 서비스의 YAML에 적힌 셀렉터는 직접 연결에 사용되는 것이 아니라 IP와 포트의 목록을 만드는 데 사용되고 엔드포인트 리소스에 그 정보가 저장된다. 클라이언트가 서비스로 연결을 시도하면 서비스 프록시는 접속정보(IP, 포트) 쌍 중에서 하나를 선택한다.
- 포트 셀렉터 없이 서비스의 YAML을 구성하고, 엔드포인트 리소스를 직접 생성할 수 있다. 다만 서비스와 동일한 이름이어야 하고, 서비스를 위한 IP와 포트를 담게 된다.
- FQDN을 통해 ExternalName유형의 리소스를 갖는 서비스를 생성하면, 외부 서비스의 별칭을 제공하는 서비스를 생성할 수 있다.
5.3 외부 서비스에서 외부 클라이언트로
- NodePort 서비스 타입
- 쿠버네티스가 모든 노드를 대상으로 포트를 예약한다.(포트 번호는 모두 같은 번호)
- 들어오는 접속을 서비스 각 부분의 포트로 보낸다. 전체 노드의 지정된 포트로의 접속은 모두 서비스로 리다이렉팅 된다.
- 이 때 클라이언트가 접근한 노드가 실패하면 클러스터에 액세스가 불가능해지기 때문에, 로드 밸런서가 필요하다. 이것은 NodePort 대신 LoadBalancer 서비스를 생성하면 자동으로 프로비전하는 것이 가능하다.
- LoadBalancer 서비스 타입
- 노드밸런서로 접속하면 NodePort에서 할당되는 포트로 하나의 로드로 연결되고, 다시 서비스로 리다이렉트된다.
- 로컬 외부 트래픽 정책을 사용하여 서비스를 구성하면 부하 분배가 고르지 못할 수 있다.
- 서비스를 이용할 경우 뒷단의 포드는 클라이언트의 IP 주소를 얻을 수 없다.
- 인그레스 리소스: 하나의 IP 주소를 통해 여러 서비스를 제공
5.4 인그레스 리소스를 이용해 외부로 서비스 노출하기
- 인그레스는 HTTP 애플리케이션 레이어에서 동작하고, 쿠키 기반 고정 세션 기능을 제공한다.
- 인그레스 리소스를 작동시키려면 클러스터에서 인그레스 컨트롤러를 실행해야 한다.
- 인그레스의 YAML에는 서비스로 메핑할 domain name, 전달될 서비스의 이름과 포트가 있다.
- domain name을 통해 서비스에 액세스하려면 인그레스 컨트롤러의 IP와 domain name이 매핑이 되어야 한다.
- 클라이언트가 domain name을 통해 포드 중 하나에 연결하려고 하면, 먼저 DNS 룩업을 통해 인그레스 컨트롤러의 IP를 가져와여 한다. 그리고 HTTP 요청을 인그레스 컨트롤러에 보내고 Host 헤더에 domain name을 지정한다. 헤더에서 컨트롤러는 액세스할 서비스를 결정하고 서비스에 지정된 엔드포인트 객체를 통해 클라이언트의 요청을 포드 하나에 전달한다.
- 인그레스의 YAML에서 path를 지정하여 다수의 서비스에 다수의 호스트와 경로를 매핑할 수 있다. 요청된 URL에 따라 각기 다른 서비스로 보내지게 된다.
- HTTPS를 이용하기 위해, TLS를 지원하도록 인그레스를 설정할 수 있다.
5.5 포드가 연결을 수락할 준비가 되었을 때 신호 보내기
- 레디니스 프로브: 주기적으로 호출되어 특정 포드의 클라이언트 요청 수락 가능 여부를 결정한다.
- Exec 프로브: 프로세스를 실행시킨다. 컨테이너의 상태는 프로세스의 종료 상태 코드에 의해 결정된다.
- HTTP GET 요청을 컨테이너에게 보내고 응답을 판단하는 HTTP GET 프로브
- TCP 소켓 프로브
- 라이브니스 프로브와 달리 컨테이너가 실패해도 종료되거나 다시 시작되거나 하지는 않는다. 단지 실패 시에는 엔드포인트 오브젝트에서 제거되어 해당 포드로 요청이 리다이렉트되지 않도록 한다.
- 레디니스 프로브는 레플리케이션컨트롤러의 YAML에서 컨테이너 스펙 밑의 레디니스 프로브 정의를 추가하여 생성할 수 있다.
- 레디니스 프로브는 항상 정의하는 것이 좋으며, 프로브에 포드의 종료 로직을 종료시키지 않아야 한다.
5.6 헤드리스 서비스 사용해 개별 포드 찾기
- 쿠버네티스는 클라이언트가 DNS 룩업을 통해 포드의 IP를 찾는 것을 허용한다. 만약 쿠버네티스에 서비스에 클러스터 IP가 필요 없다고 하면, DNS 서버는 단일 서비스 IP 대신 포드의 IP목록을 알려줄 것이고, 이를 이용해 모든 포드의 IP를 가져와 연결에 사용할 수 있다.
- 헤드리스 서비스: 서비스 스펙의 clusterIP 필드를 None으로 지정한 서비스
- 헤드리스 서비스에서 DNS 서버는 포드의 IP를 반환하기 때문에 클라이언트는 서비스 프록시 대신 포드에 직접 연결하게 된다.
5.6 서비스의 문제 해결
- 서비스를 통해 포드에 접속이 되지 않을 때 체크할 수 있는 부분
- 클러스터 IP가 대상이라는 점
- 서비스의 클러스터 IP는 가상 IP이고 핑을 보내도 응답이 없다는 점
- 레디니스 프로브를 정의했다면 성공 여부를 확인해야 한다.
- 포드가 서비스의 일부분인지 확인하려면 kubectl get endpoints 명령을 통해 알아보자.
<6장 : 볼륨 : 컨테이너에 디스크 스토리지 연결>
6.1 볼륨 소개
- 볼륨은 포드의 스펙에 정의한다. 포드의 컨테이너들에서 볼륨을 사용할 수 있지만, 각 컨테이너에 볼륨을 마운트해야 접근이 가능하다. 같은 볼륨을 다른 컨테이너에 다른 경로로 마운트할 수 있다.
- 볼륨의 수명은 포드의 수명에 바인딩 되는데, 볼륨의 유형에 따라 포드와 볼륨이 사라진 이후 볼륨의 파일이 사라질 수도 있고, 그대로 유지되어 나중에 새 볼륨에 마운트 될 수도 있다
- 볼륨의 유형에는 다음과 같은 것들이 있다
6.2 볼륨을 사용한 컨테이너 사이의 데이터 공유
- 포드 내에서 여러 컨테이너가 데이터를 공유하는 방법
- emptyDir 사용하기
- 빈 디렉터리로 사용하는 볼륨으로, 동일 포드에서 사용중인 컨테이너 간 파일을 공유할 떄 유용하다
- 대규모 sorting 등을 진행할 떄 사용하는 임시적인 데이터 기록용으로도 유용하다
- 포드를 생성할 때 다음과 같이 emptyDir 형식의 볼륨정보를 디스크립터에 기록한다. volume 항목에 볼륨 정보를 기록하고, container 정보의 volumeMounts 항목에 사용할 볼륨의 이름과 마운트 경로를 입력한다
apiVersion: v1
kind : Pod
…
spec:
conaintners:
- image : …
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
volumes:
-name : html
emptyDIr : {}
- 포드를 생성할 때 다음과 같이 emptyDir 형식의 볼륨정보를 디스크립터에 기록한다
- emptyDir 볼륨은 포드를 호스팅하는 워커 노드의 실제 디스크에 생성된다. 따라서 노드 디스크 유형에 따라 성능이 결정되며, medium : Memory 로 설정하여 디스크 대신 메모리에 있는 tmpfs 파일 시스템에 emptyDir를 생성하게 할 수도 있다
- gitRepo 사용하기
- gitRepo는 깃 리포지토리를 복제해 채워지는 emptyDir 볼륨이다.
- 디스크립터에 리포지토리 주소와 리비전, 디렉토리를 기록할 수 있다
...
volumes:
-name: html
gitRepo:
repository: https://github.com/XXX..
revision: master
directory: .
- 새 버전이 커밋되어 리포지토리를 업데이트하려면 포드를 다시 시작해야 한다는 단점이 있는데, 이를 극복하기 위해 사이드카 컨테이너를 사용하는 기법을 사용할 수 있다
6.3 워커 노드 파일 시스템에 액세스하기
- hostPath 볼륨을 이용하면 호스트 노드의 파일 시스템에 접근할 수 있다. hostPath 볼륨은 호스트 파일 시스템의 특정 파일 또는 디렉토리를 가리킨다. 포드가 사라져도 데이터가 남게 되는 영구 스토리지 유형이다
- 주로 노드에서 시스템 파일을 읽거나 써야 하는 경우, 데몬셋으로 사용되는 시스템 수준 포드에 사용된다
6.4 영구 스토리지 사용
- 모든 클러스터 노드에서 접근 가능한 영구 스토리지를 사용하는 경우, 현재까지 언급된 스토리지 유형과 다르게 NAS (Network-Attached Storage) 유형에 저장해야 한다.
- 클라우드 제공자에 따라 클라우드에서 제공하는 쿠버네티스 지원 영구 스토리지 타입을 사용할 수 있다. (ex : GKE의 gcePersistentDisk, AWS EC2의 awsElasticBlockStore, MS 애저의 azureDisk). 실제 기본 스토리지를 만들고 적절한 속성을 설정해야 한다
...
kind: Pod
…
spec:
volumes:
- name: mongodb-data
awsElasticBlockStore:
volumeId: my-volume
fsType: ext4
…
- NFS 지원 타입, ISCSI 지원타입, GFS 지원타입 등 쿠버네티스에서 여러 스토리지 타입을 지원한다
6.5 기본 스토리지 기술에서 포드 분리
- 지금까지 사용된 예시는 포드 개발자가 클러스터에서 사용할 수 있는 실제 스토리지 인프라에 대한 지식을 알고 있어야 한다.
- PersistentVolume 과 PersistentVolumeClaim 을 사용하면, 개발자가 포드를 생성할 때 CPU, 메모리 등 리소스를 요청하는 것과 같은 방식으로 영구 스토리지를 요청할 수 있다.
- 클러스터 관리자가 기본 스토리지 설정 후 PersistentVolume 리소스를 생성하여 API 서버에 등록한다
…
kind: PersistentVolume
…
spec:
capacity: //크기 정의
storage: 1Gi
accessModes: // 클라이언트들이 어떤 권한으로 마운트하게 될지
- ReadWriteOnce
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain // 클레임이 해제된 후 동작 정책
gcePersistentDisk:
pdName: mongodb
fsType: ext4
- 개발자는 필요한 스토리지 크기, 액세스 모드를 지정하여 PersistentVolumeClaim 매니페스트를 API 서버에 제출한다
…
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc
spec:
resources:
requests:
storage: 1Gi // 스토리지 1GB 요청
accessModes: // 단일 클라이언트 지원
- ReadWriteOnce
storageClassName: “”
- 쿠버네티스가 적절한 영구 볼륨을 찾아 PVC에 바인딩한다
- 바인딩된 PVC를 삭제해 릴리스될 때 까지 다른 사용자는 동일한 PersistentVolume을 사용할 수 없다
- 포드 디스크립터에 사용하고자 하는 PVC를 기록하여 스토리지를 사용한다
…
Kind: Pod
…
spec:
…
volumes:
- name: mongodb-data
persistentVolumeClaim:
claimName: mongodb-pvc
- PersistentVolume이 릴리즈될 후 수동으로 재사용(리클레임) 할 수 있는 방법은 리소스를 삭제하고 다시 작성하는 것이다. 리클레임 정책을 Retain으로 설정했을 때의 경우이다
- 리클레임 정책을 Recycle 로 설정한 경우 볼륨 내용을 삭제하고 다시 할당할 수 있게 만들며, Delete로 설정하는 경우 기본 스토리지를 삭제한다. 스토리지 타입에 따라 특정 정책만 지원할 수 있어 확인하고 설정해야 한다
6.6 PersistentVolume의 동적 프로비저닝
- 쿠버네티스에서 PersistentVolume을 동적 프로비저닝을 통하여 자동으로 스토리지 프로비저닝을 할 수 있다
- 클러스터 관리자가 PersistentVolume을 만드는 대신 PersistentVolume 공급자를 배포하고, 사용자가 원하는 PV 유형을 선택할 수 있도록 StorageClass 오브젝트를 정의할 수 있다
- PV를 미리 여러개 프로비저닝하는 대신, 스토리지 클래스를 정의하고 사용자가 PVC를 이용하여 스토리지를 요청하는 경우 새로운 PV를 동적으로 생성할 수 있게 한다
- 다음 과정으로 스토리지클래스 오브젝트가 사용된다
- 관리자가 StorageClass 리소스를 생성한다
…
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/gce-pd // PV 프로비저닝에 사용할 볼륨 플러그인
parameters: // 제공자에게 전달될 매개변수 (제공 업체 플러그인에 의존한다)
type: pd-ssd
zone: europe-west1-b
- 사용자가 PVC에서 StorageClass를 참조한다
…
kind: PersistentVolumeClaim
…
spec:
storageClassName: fast
resources:
requests:
storage: 100Mi
accessModes:
-ReadWriteOnce
- PV가 스토리지클래스에서 참조되는 제공자에 의해 생성된다.
- 스토리지클래스를 참조할 때 이름을 이용해서 참조하기 때문에, 스토리지 클래스의 이름이 동일한 경우라면 PVC 정의를 다른 클러스터에 이식할 수 있다는 장점이 있다
- PVC가 동적으로 프로비저닝되는 PV가 아닌 사전에 프로비저닝된 PV를 사용하고 싶은 경우, 디스크립터에서 StorageClassName을 “”로 명시적으로 설정하면 된다
<7장 : ConfigMap과 시크릿:애플리케이션 설정>
7.1 컨테이너화된 애플리케이션 설정
-쿠버네테스에서 설정 데이터를 저장하는 리소스를 ConfigMap이라고 하고, 그 기능을 알아본다.
-설정 데이터를 저장하기 위해 ConfigMap을 사용하고 있는지의 여부와 관계없이 다음과 같이 애플리케이션을 설정할 수 있다.
- 컨테이너에 명령어 인자 전달
- 컨테이너의 사용자 정의 환경 변수 설정
- 특별한 볼륨 타입을 통해 컨테이너에 설정 파일을 마운트
7.2 컨테이너에 명령행 인자 전달
-컨테이너에서 실행되는 전체 명령은 명령과 인자 정의를 두 부분으로 설정되고 ENTRYPOINT와 CMD 이 두명령어는 도커 파일에서 두파트를 정의한다.
- ENTRYPOINT는 컨테이너가 시작됐을 때 호출해야 할 실행 파일을 정의한다.
- CMD는 ENTRYPOINT로 전달할 인자를 지정한다.
-shell과 exec형식 간의 두 명령어가 지원하는 형식이 다르다.
- shell 형식 : ENTRYPOINT node app.js
- exec 형식 : ENTRYPOINT [“node”, “app,js”]
-쿠버네티스에서 컨테이너를 지정할 때 ENTRYPOINT와 CMD 모두 재정의하도록 선택할 수 있고, 이렇게 하려면 컨테이너 스펙에서 command와 args속성을 통 해 설정해야한다.
| 도커 | 쿠버네티스 | 설명 |
| ENTRYPOINT | Command | 컨테이너 내부에서 실행되는 실행 파일 |
| CMD | args | 실행 파일에 전달된 인자 |
7.3 컨테이너의 사용자 정의 환경 변수 설정
-컨테이너화된 애플리케이션은 설정 옵션을 제공하기 위해 환경 변수를 사용한다. 따라서 쿠버네티스를 사용하면 포드의 각 컨테이너를 위한 환경 변수의 사용자 정의 목록을 지정할 수 있다.
-새로운 이미지를 빌드한 후 도커 허브로 푸시하고 컨테이너 정의에 환경 변수를 포함시킨 스크립트에 이를 전달해 새 포드를 생성하고 실행할 수 있다. 즉, 포드 수준이 아닌 컨테이너 정의 내부에서 환경변수를 설정한다.
-포드 정의에서 효과적으로 값을 하드코딩하려면 프로덕션 및 개발 포드를 위한 분리된 포드 정의가 필요하다. 즉, 여러 환경에서 동일한 포드 정의를 재사용하려면 포드 디스크립터에서 설정을 분리하는 것이 좋다.
7.4 ConfigMap을 통한 설정 분리
-쿠버네티스는 설정 옵션을 ConfigMap이라는 별도의 객체로 분리할 수 있다. 이 객체는 간단한 문구 부터 전체 설정 파일에 이르는 값을 키/값 쌍을 포함하는 맵이다. 애플리케이션은 ConfigMap을 직접 읽거나 그것의 존재를 알 필요 없고, 맵의 내용은 환경 변수 또는 볼륨의 파일로 컨테이너에 전달된다..
-kubectl create configmap 명령을 사용하여 ConfigMap을 생성해 맵의 엔트리를 정의할 수 있다. 파일 내용으로 생성하는 방법이나 , 디렉터리에 있는 파일로 부터 생성하는 다양한 옵션이 있다.
-ConfigMap의 값을 포드의 컨테이너로 가져오는 방법으로는 3가지 옵션이 있다
- ConfigMap의 모든 항목을 한번에 환경 변수로 전달
- ConfigMap 항목을 명령행 인자로 전달
- ConfigMap 엔트리를 파일로 노출하기 위해 ConfigMap 볼륨 사용
-환경 변수 또는 명령행 인자를 설정 소스로 사용할 때의 단점 중 하나는 프로세스가 실행하는 동안 환경 변수 또는 명령행 인자를 업데이트할 수 없는데, ConfigMap을 사용해 볼륨을 통해 노출 시 포드를 다시 만들거나 컨테이너를 다시 시작하지 않고 설정을 업데이트할 수 있다.
7.5 시크릿으로 컨테이너에 민감한 데이터 전달하기
-쿠버네티스는 중요한 정보를 저장하고 분류하기 위해 시크릿이라는 별도의 객체를 제공한다. 시크릿은 ConfigMap과 비슷하고 키/값 쌍으로 사용할 수 있다.
- 환경 변수로 시크릿 엔트리를 컨테이너에 전달할 수 있다.
- 볼륨의 파일로써 시크릿 엔트리를 노출할 수 있다.
-시크릿과 ConfigMap을 언제 사용해야 하는지를 잘 선택해야한다.
- 민감하지 않은 일반 설정 데이터를 저장 시 COnfigMap을 사용한다.
- 시크릿은 본질적으로 민감한 데이터를 저장할 때 사용한다. 설정 파일에 중요한 데이터와 중요하지 않은 데이터가 모두 포함돼 있을 경우, 시크릿으로 저장한다.
-시크릿과 ConfigMap의 차이로는 시크릿의 내용은 Base64로 인코딩된 문자열로 표시하는 반면, ConfigMap의 경우 일반 텍스트로 표시한다. 입력내용을 설정하고 읽을 때 인코딩하고 디코딩해야 하기 때문에 YAML과 JSON 형태로 시크릿을 작성하는 것이 더 어렵다.
-포드에서 시크릿을 사용하기 위해 cert와 key 파일 모두 포함하는 forune-http 시크릿으로 구성하고 이를 사용하려면 Ngnix가 이를 사용하도록 설정하여야한다.
-쿠버네티스 자체에서 자격 증명을 전달해야 할 때가 있는데, 이 또한 시크릿을 통해 이뤄진다. 지금까지 모든 컨테이너 이미지가 공용 이미지 레지스트리에 저장됐으므로 특별한 자격 증명이 필요가 없었지만, 대부분의 조직은 자신의 이미지에 대해 개인 이미지 레지스트리를 사용한다. 따라서 개인 레지스트리에 있는 컨테이너 이미지를 위한 포드를 배포시 쿠버네티스를 이미지를 가져오기 위해 자격 증명이 필요하다.
-도커 허브는 공용 이미지 레포지터리 외에도 개인 레포지터리를 만들 수 있다.
- 도커 레지스트리에 대한 자격 증명이 있는 시크릿을 만든다.
- 포드 매니페스트의 imagePullSecrets 필드에서 시크릿을 참조한다.
- 도커 레지스트리로 인증하기 위한 자격 증명을 보유하고 있는 시크릿을 생성하고, 쿠버네티스가 개인 도커 허브 스토리지에서 이미지를 가져올 때 시크릿을 사용하게 하려면 포드 스펙에 시크릿의 이름 지정하면 된다.
<8장 : 애플리케이션에서 포드 메타 데이터와 그 외의 리소스에 접근하기>
8.1 Downward API를 통한 메타 데이터 전달
- 포드 설치 이후의 데이터(pod의 ip, host node의 이름, pod의 특정 이름: 레플리카로 만들 경우 등)이 필요한 경우, 기존에 배웠던 ConfigMap이나 Secret으로는 해결할 수 없다. 이를 해결하기 위한 것이 바로 'Downward API'다.
- 애플리케이션에서 API를 요청하여 얻는 데이터가 아니라 k8s api server가 환경변수와 downward API 볼륨에 담아준다.
- 사용 가능한 메타 데이터(345p)
- 포드 이름
- 포드 IP
- 포드가 속한 namespace 이름
- 포드가 실행되는 노드의 이름
- 포드가 실행 중인 서비스 계정의 이름
- 컨테이너의 CPU 및 메모리 요청
- 컨테이너의 CPU 및 메모리 한계
- 포드의 라벨
- 포드의 주석
- 실행 시 환경설정 값을 담는 기능은 실행중에 변경 불가
- 라벨과 주석은 변경 가능하므로 주로 환경변수보다는 볼륨에 담아서 씀
- 볼륨은 환경변수에 쓰이는 변수가 다른 컨테이너(동일한 포드에서)에 전달하는 패턴에도 사용함
- 메타데이터가 상당히 제한적이지만 셸 스크립트나 코드 필요 없이 간단히 쓰기 좋다.
8.2 쿠버네티스 API 서버와 통신하기
8.2.1. 쿠버네티스 REST API 탐색
kubectl cluster-info
kubectl proxy
8.2.2. 포드 내에서 API 서버와 통신
- 디폴트 네임스페이스에 생성된 쿠버네티스에 요청하면 가능하다.
8.2.3. 앰배서더 컨테이너와의 API 서버 통신 간소화
- 포드 내에서 API 서버와 직접 통신하는 대신, 메인 컨테이너 옆의 '앰배서더 컨테이너'에서 kubectl proxy를 실행하고 이를 이용해 API 서버와 통신하게 할 수 있다. 주 컨테이너의 애플리케이션은 HTTPS 대신 HTTP를 사용해 앰배서더에 연결하고 보안 역할을 담당하는 앰배서더 프록시가 API 서버에 HTTPS를 연결하게 한다. 이는 기본 토큰의 시크릿 볼륨 파일을 사용해 수행한다.
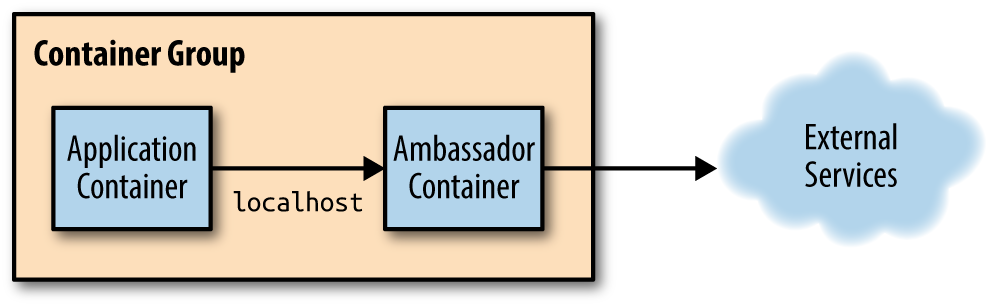
kubectl exec -it curl-with-ambassador -c main bash
8.2.4. 클라이언트 라이브러리를 사용해 API 서버와 통신
- 현재 API Machinery SIG에서 지원하는 쿠버네티스 API 클라이언트 라이브러리는 고랭 클라이언트, 파이썬의 두 종류이며, 자바(Fabric8, Amdatu), Node.js(Tenxcloud, GoDaddy), PHP, Ruby, Clojure, Scala, Perl 등에 대해서도 사용자 제공 클라이언트 라이브러리가 있다. 이런 라이브러리는 대개 HTTPS를 지원하고 인증을 처리하므로 앰배서더 컨테이너를 사용할 필요가 없다.
<9장 : 디플로이먼트: 애플리케이션을 선언적으로 업데이트하기>
9.1 포드에서 실행중인 애플리케이션 업데이트
- 애플리케이션 업데이트 등으로 인해 모든 포드를 새로운 버전으로 업데이트 하는 데에는 크게 두 가지 방법이 있다
- 기존의 모든 포드를 삭제한 후 새로운 포드 시작 : 레플리케이션 컨트롤러에서 새로운 버전을 참조하도록 템플릿을 수정한 후 기존 포드를 전부 내리면 된다. 애플리케이션을 실행할 수 없는 짧은 시간이 발생하는 문제 존재. 다운타임을 허용한다면 가장 간단한 방법이다.
- 새로운 포드를 시작하고 끝나면 오래된 것을 지운다 : 한번에 버전을 바꾸는 방법과 롤링 업데이트 두 가지 방법이 있다.
9.2 레플리케이션컨트롤러를 통한 자동 업데이트
- 수동 롤링 업데이트는 단계가 복잡하기 때문에, kubectl을 이용하여 자동 롤링 업데이트를 수행할 수 있다.
- 단일 YAML 파일을 만들고 단일 kubectl create 명령을 이용하여 YAML 파일 내에 기재한 여러 객체를 게시할 수 있다. YAML 매니페스트 내에서 세 개의 대시를 포함항 행으로 여러 객체를 구분하여 포함할 수 있다
apiVersion: v1
kind : ReplicationControllwer
…
---
apiVersion: v1
kind : Service
…
- kuberctl rolling-update 명령을 이용하여 자동 롤링 업데이트를 수행할 수 있다. 해당 명령에서 교체할 레플리케이션컨트롤러와 새 레플리케이션컨트롤러의 이름을 지정하고 교체할 새 이미지를 지정하면 된다
$ kubectl rolling-update kubia-v1 kubia-v2 --image=luksa/kubia:v2
- kubectl을 통해 rolling-update를 수행하면 레플리케이션컨트롤러의 라벨 셀렉터를 사전에 수정하여 롤링 업데이트를 수행할 수 있게 한다. 새로운 레플리케이션컨트롤러와 기존 레플리케이션컨트롤러는 다른 deployment 라벨 값을 가지고 있다
- kubectl은 사전 설정이 끝난 후 새 컨트롤러를 스케일 업 하여 하나씩 포드를 교체해나간다. 첫번째 v2 포드를 만든 후 이전 레플리케이션컨트롤러의 포드를 하나씩 줄인다. 서비스는 기존/새로운 포드에 공통적으로 들어간 라벨 값을 대상으로 하므로 서비스에 대한 요청이 점차 새로운 버전의 포드로 리다이렉션 된다
- 지금까지 설명한 kubectl을 이용한 롤링 업데이트는 더이상 사용되지 않는다.
- 쿠버네티스가 포드의 라벨과 레플리케이션의 라벨 셀렉터를 강제로 수정하며 이는 사용자가 보편적으로 기대하는 동작이 아니다
- 쿠버네티스 마스터가 아니라 kubectl 클라이언트가 스케일링을 수행하게 되어있다. 따라서 kubectl이 업데이트를 수행하는 동안 네트워크가 끊어지게 되면 포드와 레플리케이션 컨트롤러는 중간 상태에 놓이게 된다
- 쿠버네티스가 지향하는 사용 방식은 상태를 선언적으로 말하는 것이다
9.3 선언적으로 애플리케이션을 업데이트하기 위한 디플로이먼트 사용하기
- 디플로이먼트는 애플리케이션을 배포하고 이를 선언적으로 업데이트하기 위해 사용하는 레플리케이션컨트롤러/레플리카셋 상위 수준의 리소스다.\
- 디플로이먼트를 만들면 레플리카셋 리소스가 아래에 만들어지고 레플리카셋이 포드를 복제하고 관리한다
- 디플로이먼트도 매니페스트를 통해 생성할 수 있으며 라벨 셀렉터, 원하는 복제본 수, 포드 템플릿으로 구성된다. 디플로이먼트 리소스가 수정될 때 업데이트 수행 방법을 정의하는 전략을 지정할 수 있다
apiVersion: apps/v1beta1
kind : Deployment
metadata:
name : kubia //디플로이먼트 내에서 여러 버전이 실행될 수 있으므로
이름이 애플리케이션 버전을 참조하지 않음
spec:
replicas: 3
...
- kubectl rollout status deployment [이름] 명령을 이용하여 디플로이먼트의 롤아웃 상태를 출력할 수 있다
- 디플로이먼트 내의 포드 리스트를 출력하면 이름 중간에 해시값이 들어있는 것을 확인할 수 있으며, 이는 레플리카셋의 해시값과 일치한다. 즉, 디플로이먼트 포드 템플릿의 주어진 버전에 따라 동일한 레플리카셋이 사용된다
- 디플로이먼트 사용시 kubectl rolling-update 등 별도 명령을 이용하지 않고 리소스에 정의된 포드 템플릿만 수정하면 된다
- 디플로이먼트 전략은 디폴트인 RollingUpdate와 Recreate가 있으며, Recreate는 앞서 언급한 방식으로 모든 기존 포드를 삭제한 후 새로운 포드를 생성하는 것이다 (기존 버전을 완전히 중지하고 새 버전을 시작해야 하는 경우)
- RollingUpdate는 오래된 포드를 하나씩 제거하는 동시에 새로운 포드를 추가하는 것으로, 원하는 복제본 수가 포드 수보다 크거나 작은 상한을 구성할 수 있다.
- kubectl patch 명령을 사용하면 텍스트 편집기 사용 없이 리소스의 단일 속성이나 값을 변경할 수 있다
- 디플로이먼트의 minReadySconds 속성을 변경하여 업데이트 프로세스 속도를 조절할 수 있다
- kubectl set image 명령을 이용하여 컨테이너를 포함하는 모든 리소스의 이미지를 변경할 수 있다
$ kubectl set image deployment kubia nodejs=luksa/kubia:v2
- 롤링 업데이트가 시작되면 디플로이먼트 내부에서 추가 레플리카셋이 생성되고 이전 레플리카셋의 포드 수가 0으로 축소되는 동안 느리게 확장된다
- 새로운 버전의 포드에 오류가 발생한 경우, kubectl rollout undo deployment 명령을 이용하여 롤아웃을 쉽게 되돌릴 수 있다.
- 오래된 레플리케이션은 업데이트가 끝난 이후에도 삭제되지 않고 남아있는데, 롤아웃 히스토리를 볼 수 있게 하기 위함이다. kubectl rollout history 명령을 이용하여 디플로이먼트에 대한 롤아웃 이력을 확인할 수 있다. 디플로이먼트를 만들 때 --record 옵션을 사용하여 리비전 히스토리에서 버전 변경 원인을 확인할 수 있다
- kubectl rollout undo 명령에서 --to-revision 옵션을 이용하여 특정 리비전으로 되돌릴 수 있다
- 디플로이먼트 매니페스트에서 디플로이먼트 전략 속성의 rollingUpdate 하위 속성인 maxSurge와 maxUnavailable 속성을 이용하여 롤아웃 속도를 통제할 수 있다. 값으로 절대값과 비율 퍼센트를 사용할 수 있다
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
- maxSurge : 배포에 구성된 원하는 복제본 수를 초과하여 존재하도록 허용하는 포드 인스턴스 수
- maxUnavailable : 업데이트 중 원하는 복제본 수에 대해 사용할 수 없는 포드 인스턴스의 수
- kubectl rollout pause 명령을 이용하여 롤아웃을 일시 중지할 수 있다
- kubectl rollout resume 명령을 이용하여 롤아웃을 재개할 수 있다
- 잘못된 버전의 롤아웃을 방지하기 위해 적절한 minReadySeconds 속성값과 레디네스 프로브를 사용하면 된다
- minReadySeconds 에 설정된 시간이 지나가기 전에 레디네스 프로브의 시작이 실패하기 시작하면 새로운 버전의 롤아웃이 차단된다
- 디플로이먼트 스펙의 progressDeadlineSeconds 속성을 이용하여 롤아웃 데드라인을 설정할 수 있다. 롤아웃이 데드라인 안에 진행되지 않으면 실패한 것으로 간주된다