Database
정의
- 사용자가 데이터베이스와 상호작용하면서 데이터를 다루는 프로그램
구성
- 데이터파일 + 컨트롤 파일 + 리두로그파일
- 구조화된 데이터 집합
특징
- 영구저장소
- 큰 데이터를 영구적으로 저장
- 프로그래밍 인터페이스
- 사용자들이 데이터를 쉽게 다룰 수 있도록 SQL 제공
- 트랜잭션 지원
- ACID 특성
3계층 구조
- 프레젠테이션 계층
- 비즈니스 계층
- 데이터 계층
SQL
정의
- RDBMS 프로그래밍 언어
명령어
- DDL(Data Definition Language)
- 데이터 담는 보관용기에 관한 명령어
- DML(Data Manipulation Language)
- 데이터 조작과 관련한 명령어
데이터 타입
- 문자열
- CHAR, VARCHAR, NCHAR, NVARCHAR
- 비트 array
- BIT
- BIT VARYING
- 숫자
- INTEGER
- SMALLINT
- FLOAT
- REAL
- DOUBLE PRECISION
- NUMERIC(p,s)
- DECIMAL(p,s)
- 날짜와 시간
- DATE(연.월.일)
- TIME(시.분.초)
- TIME WITH TIME ZONE
- TIMESTAMP(DATE+TIME)
- TIMESTAMP WITH TIMAE ZONE
관계형 모델 이론
조직의 업무에서 사용하는 데이터를 어떻게 구성하고, 조작하며, 데이터 조작 시 데이터가 어떻게 반응해야 하는지에 대한 것. ACID 중 C(일관성)이 이를 표현한다고 볼 수 있다.
DML

R1 ... Rm: (테이블)
condition: (필터 조건)
A1 ... An: (출력내용)
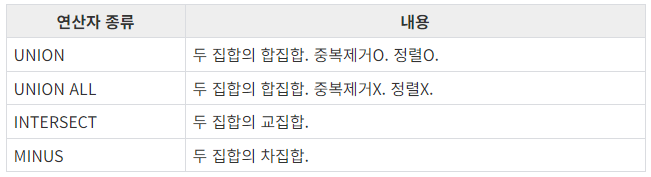
- Set operators(집합 연산)
- Join
- Cross Join
- select * from A cross join B;
- Inner Join
- select a, b from table_A inner join table_B on a.id=b.id;
- select a, b from table_A, table_B where a.id=b.id;
- cross join의 원소 중 조건을 만족시키는 원소들을 출력시키는 것
- Natural Join
- Join 하려는 테이블의 컬럼명과 기존 테이블 컬럼명이 같아야 함
- 위 칼럼을 Join 할 때 데이터 타입도 같아야 함
- Using을 사용해 조인하려는 칼럼을 지정할 수도 있음
- Outer Join
- LEFT OUTER JOIN
- LEFT TABLE의 모든 데이터가 출력이 되는 것으로 JOIN이 됨
- 1 : N 관계에서도 성립
- RIGHT OUTER JOIN
- FULL OUTER JOIN
- LEFT OUTER JOIN
- Subquery
- Select, From, Where 어느 절이든 다 들어갈 수 있음
- From 절에 들어가는 Subquery를 inline view라고 함
- Value로서 의미를 갖는 것은 Scalar Subquery
- Aggregation(집계)
- min
- max
- sum
- avg
- count
- Analytic Funtions
- Cross Join
- connect by
- Join Algorithm
- Nested Loop Join
- Hash Join
- Sort Merge Join
NULL
- UNKNOWN
- UNDEFIENED
- 미지의 VALUE
DUAL TABLE
- Dummy row 하나를 가지는 테이블
- 상수 값 등을 얻을 때 사용할 수 있음
격리수준에 따라 발생하는 현상
- 팬텀 리드(Phantom Read)
- 한 트랜잭션 내 동일한 쿼리를 보냈을 때 조회 결과가 다른 경우
- 다른 트랜잭션에 의해 행이 추가돼서 발생한다.
- REPEATABLE_READ 격리 수준부터 발생한다.
- 반복가능하지 않은 조회(Non-repeatable Read)
- 한 트랜잭션 내 같은 행에 두번이상 조회가 발생했을 때 그 값이 다른 경우
- 다른 트랜잭션에 의해 특정 행이 업데이트 됐을 때 발생한다.
- 더티 리드(Dirty Read)
- 다른 트랜잭션이 커밋하지 않은 데이터를 읽는다.
- READ_UNCOMMITTED 격리 수준부터 발생한다.
격리수준
- SERIALIZABLE
- 트랜잭션을 순차적으로 진행
- 여러 트랜잭션이 같은 행에 접근할 수 없음
- REPEATABLE_READ
- 하나의 트랜잭션이 수정한 행을 커밋 이전에 다른 행이 수정할 수 없음
- 다른 트랜잭션에 의해 새로운 행이 추가되는 것은 가능
- READ_COMMITTED
- 다른 트랜잭션이 커밋하지 않은 정보를 읽을 수 없음
- 커밋 완료된 데이터만 조회할 수 있음
- 많은 DB가 채택하는 격리 수준
- READ_UNCOMMITTED
- 다른 트랜잭션이 커밋하지 않은 정보를 읽을 수 있음
MVCC(Multi-version Read Consistency)
- 한 테이블에 대해 여러 버전으로 동시에 읽을 수 있는 기능
Objects
Schema Objects
- 특정 스키마가 속하는 objects
Non-Schema Objects
- 어느 스키마에도 속하지 않는 objects
- Users
- Tablespaces
- Undo Segments
- Roles
- Profiles
- Directories
Schema
- 스키마는 일반적인 의미에서 메타데이터의 집합
Table
- column들이 정의되고 거기에 맞는 데이터를 저장하는 object
Index
- Table의 특정 column 혹은 column의 집합, 연산 결과 등을 이용해 Table의 row들을 indexing 해주는 object
- B+ tree 구조를 가진다.
- leaf node 단위 row는 key + rowid
- ROWID(주소값)을 통해 table에 있는 실제 row를 찾아갈 수 있음
Index Organized Table(IOT)
- Table과 index를 합쳐놓은 모양
View
- 자주 쓰는 쿼리를 저장하여 table 처럼 select 할 수 있도록 한 object
Materialized view
- 실제 데이터를 데이터블록에 저장함
- 원본 테이블이 수정되었을 때 materialized view에서는 안보임
Database Link
- 다른 Database와 연결시켜주는 objects
- DBLink 라고 함
- Tibero Database A에서 DBLink를 통해 Tibero database B에 있는 table에 접근할 수 있음
Sequence
- 순차적으로 값을 주는 object
Procedure
- SQL/PSM: DBMS에서 절차적 작업을 하기위한 표준 언어
- PL/SQL: Oracle이 만든 절차적 작업을 하기 위한 확장기능 언어. PSM과 비슷
- PL/SQL, SQL/PSM 등을 이용해 Procedure를 생성/저장 할 수 있다.
- Server에 컴파일 된게 저장되어 호출하면 그걸 수행한다.
- 리턴 값이 없다
Function
- PL/SQL, SQL/PSM 등을 이용해 Function을 생성/저장 할 수 있다.
- 리턴값이 있다.
External Procedure
- Java나 C 등을 이용해 구현하여 DB 외부에 library로 놓고, DB에서 그 library를 호출
- DB로는 수행하기 힘든 복잡한 수식 계산 등을 수행할 수 있다.
Package
- 비슷한 기능을 수행하는 procedure, function 등을 모아 패키지화 해 놓은 것
- 기본 패키지(DBMS_TPR, DBMS_LOB ... )
Trigger
- 테이블에 어떤 이벤트가 발생했을 때 미리 저장된 PL/SQL 명령이 자동으로 수행되도록 하는 object
- 문법은 procedure나 function 생성하는 것과 비슷
Synonym
- 원하는 객체에 영구적인 alias를 생성해주는 것
- CREATE synonym synonym_test(alias) for test(테이블명);