📖 쪽집게 과외
입출력
1. 사용자로부터 값을 입력 받는 방법
* System.out.printf vs System.out.print vs System.out.println
System.out.printf포맷을 지정해서 특정 변수에 있는 값을 프린트 할 수 있다.
Systemout.print입력한 문자열을 출력해 준다. 개행은 없다.
Systemout.println입력한 문자열을 출력해 준다. 개행은 있다.
2. 모니터 화면에 값을 출력하는 방법
* Scanner nextLine Scanner nextInt
import java.util.Scanner;
public class Scan {
public void printString() {
System.out.println("이름을 입력하세요.");
Scanner scanString = new Scanner(System.in);
String line = scanString.nextLine();
System.out.println("입력하신 이름은 " + line + "입니다.");
}
public void printInt() {
Scanner scanInt = new Scanner(System.in);
Integer num = scanInt.nextInt();
System.out.println(num);
}
public static void main(String[] args) {
Scan scan = new Scan();
scan.printString();
}
}이름을 입력하세요.
sjh
입력하신 이름은 sjh입니다.
Process finished with exit code 0변수, 자료형
변수를 사용하는 이유?
1. 이름을 붙임으로써 값의 특성에 대해 보다 더 잘 알기 위함이다.
2. 쉽게 값을 바꾸기 위함이다.
자료형
boolean
1비트 메모리 차지
true or false 값을 설정
JVM에서 처리하는 실제 크기는 1비트가 아닐 수 있다
int
4바이트 메모리 차지
-2^32 ~ 2^31-1 범위 내 정수를 표현할 수 있다
long
8바이트 메모리 차지
0 ~ 2^64-1 범위의 정수를 표현할 수 있다
double
8바이트 메모리 차지
-1.7E308 ~1.7E308 범위 내 크기의 실수를 표현할 수 있다
String
자바에서 기본 타입은 X. String 클래스 객체 O
short vs char
공통점
2바이트를 차지한다
public class Main {
public static void main(String[] args) {
char letter = 'A';
System.out.println("The value of letter is: " + letter);
short number = 100;
System.out.println("The value of number is: " + number);
}
}차이점
short의 경우 정수를 표현하기 위함
char의 경우 문자를 표현하기 위함
아이유 프로필 출력하기
public class IU {
String name = "아이유";
short age = 30;
boolean bool = true;
float weight = 40.5f;
long property = 10000000000L;
public void profilePrint() {
System.out.println("이름 : " + name);
System.out.println("나이 : " + age);
System.out.println("대학생인가요? : " + bool);
System.out.println("몸무게 : " + weight);
System.out.println("재산 : " + property);
}
public static void main(String[] args) {
IU iu = new IU();
iu.profilePrint();
}
}이름 : 아이유
나이 : 30
대학생인가요? : true
몸무게 : 40.5
재산 : 10000000000
Process finished with exit code 0연산자
& |
비트 연산에 사용하는 기호이다. 2가지 종류의 비트 연산이 있다. 비트 논리 연산, 비트 시프트 연산
비트 논리 연산
AND: 두비트 모두 1이면 1. 그렇지 않으면 0
OR: 두 비트 모두 0이면 0. 그렇지 않으면 1
XOR: 두 비트 다르면 1. 같으면 0
NOT: 1을 0으로, 0을 1로
byte flag;
...
if (flag & 0b00001000 == 0) System.our.print("온도는 0도 이하");
else System.our.print("온도는 0도 이상");위 코드는 AND 연산자로 flag의 비트의 3번 째 자리 수가 1인지판별하는 코드이다.
&, I 를 사용하지 않고 && || 을 사용하는 이유
비트 시프트 연산
a >> b
a의 각 비트를 오른쪽으로 b번 시프트한다. 최상위 비트는 시프트 전 최상위 비트로 채운다.
a << b
a의 각 비트를 왼쪽으로 b번 시프트한다. 최하위 비트의 빈자리는 항상 0으로 채운다.
위와 같은 이유로 && || 을 사용한다.
연습문제
public class test {
public static void main(String[] args) {
byte a, b, c, d;
a = 10;
b = 5;
c = 3;
d = 5;
int res = (((a+b)*c)/5) % 7;
System.out.print(res);
}
}2
Process finished with exit code 0아래의 출력값이 0.5가 나오게 만드는 방법
public class test {
public static void main(String[] args) {
int a, b;
a = 5;
b = 10;
System.out.println((float)a/b);
}
}형변환을 하지 않으면 정수 간 나눗셈에서 발생 한 소수점 자리수는 버림처리 된다.
보너스 3등분 하기
import java.util.Scanner;
public class Bonus {
public void threeDivde() {
System.out.println("보너스 금액을 입력하세요.");
Scanner scan = new Scanner(System.in);
double bonus = scan.nextInt();
double res = bonus/3;
System.out.printf("3등분된 보너스 금액은 %.13f원 입니다.", res);
}
public static void main(String[] args) {
Bonus b = new Bonus();
b.threeDivde();
}
}보너스 금액을 입력하세요.
1000
3등분된 보너스 금액은 333.3333333333333원 입니다.
Process finished with exit code 0이게 3의 배수일까요?
import java.util.Scanner;
public class isThreeMultiple {
public void isThreeMultiple() {
System.out.println("3의 배수인지 판단하고 싶은 숫자를 입력하세요.");
Scanner scan = new Scanner(System.in);
int input = scan.nextInt();
if (input % 3 == 0)
System.out.print("3의 배수입니다.");
else
System.out.print("3의 배수가 아닙니다.");
}
public static void main(String[] args) {
isThreeMultiple obj = new isThreeMultiple();
obj.isThreeMultiple();
}
}3의 배수인지 판단하고 싶은 숫자를 입력하세요.
19
3의 배수가 아닙니다.
Process finished with exit code 03의 배수인지 판단하고 싶은 숫자를 입력하세요.
18
3의 배수입니다.
Process finished with exit code 0
🎯 2회차 미션
JSCODE 학교의 시험 채점기
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Scanner;
public class jscode {
public void printShort(String str) {
System.out.println(str);
}
public byte input() {
Scanner scan = new Scanner(System.in);
byte num = scan.nextByte();
return num;
}
public void mission(byte num, byte gHtml, byte gCss, byte gJavascript) {
byte max = 0;
byte min = 101;
double average = ((double)(gHtml + gCss + gJavascript))/3;
ArrayList<Byte> array = new ArrayList<>(Arrays.asList(gHtml,gCss,gJavascript));
for(byte i = 0; i < array.size(); i++) {
Byte element = array.get(i);
if (element > max)
max = element;
if (element < min)
min = element;
}
array.remove(Byte.valueOf(max));
array.remove(Byte.valueOf(min));
byte mid = array.get(0);
if (max == mid && mid == 100)
System.out.println("합격입니다.");
else if (num==3)
if (average >= 70)
System.out.println("합격입니다.");
else
System.out.println("불합격입니다.");
else if (num==1 || num==2)
if (average >= 60)
System.out.println("합격입니다.");
else
System.out.println("불합격입니다.");
System.out.println("전체 과목 중 최고점은 " + max + "점 입니다.");
System.out.println("전체 과목 중 최저점은 " + min + "점 입니다.");
if (average - (int)(average) == 0)
System.out.printf("전체 과목의 평균은 %.1f점 입니다.", average);
else
System.out.printf("전체 과목의 평균은 %.14f점 입니다.", average);
}
public void mission1() {
mission obj = new mission();
obj.printShort("몇 기인지 입력해주세요");
short num = obj.input();
obj.printShort("HTML 과목 점수를 입력해주세요.");
short gHtml = obj.input();
obj.printShort("CSS 과목 점수를 입력해주세요.");
short gCss = obj.input();
obj.printShort("Javascript 과목 점수를 입력해주세요.");
short gJavascript = obj.input();
obj.mission(num, gHtml, gCss, gJavascript);
}
public static void main(String[] args) {
mission m = new mission();
m.mission1();
}
}
🎯 2회차 미션
JVM에 대해 설명해주세요
표어
Write Once Run AnyWhere
탄생배경
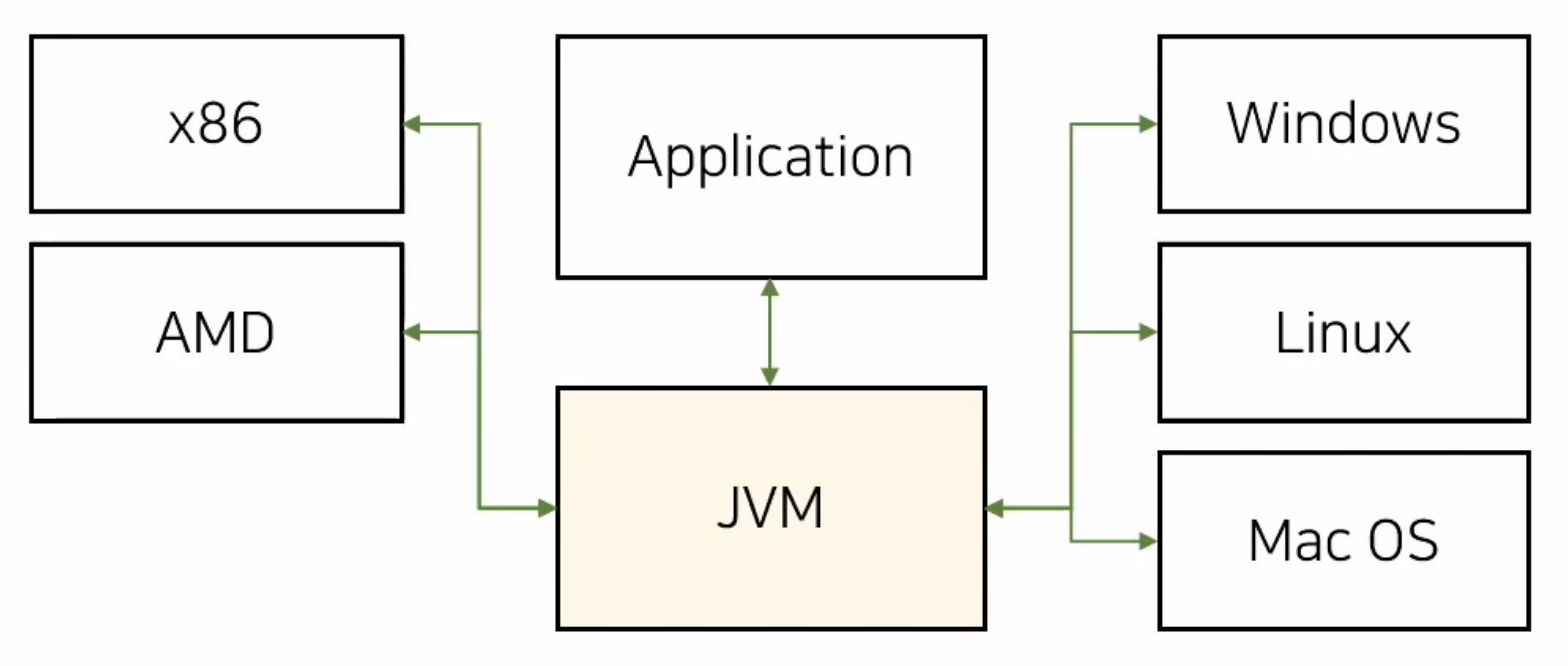
C 언어의 경우 코드 내용이 같다고 하더라도 해당 코드가 실행되는 머신의 종류에 따라 머신에 맞는 컴파일러가 필요했다. 이런 불편함을 해소하고자 JVM이 탄생하게 되었다. 표어에서 알 수 있듯이 JVM이 설치되어 있다면 CPU 종류(AMD, X86)와 운영체제(Window, Linux, Mac OS)에 상관없이 자바코드에서 기계어로 번역할 수 있다.
역할
JVM은 바이트 코드가 실행되는 시점에서 기계어로 번역하는 역할을 수행한다. JAVA로 작성한 언어를 컴파일 할 경우 바이트 코드가 생긴다. 바이트 코드의 경우 그 특성이 사람이 읽는 자바 언어와 컴퓨터 언어가 읽는 기계어의 중간 단계에 위치해있다. 터미널에 javac Hello.java를 입력하면 같은 위치 Hello.class 파일이 생긴다. 바이트 코드로 번역되어 있다. 이 바이트 코드를 기계어로 번역해주는 역할을 수행한다.
구성
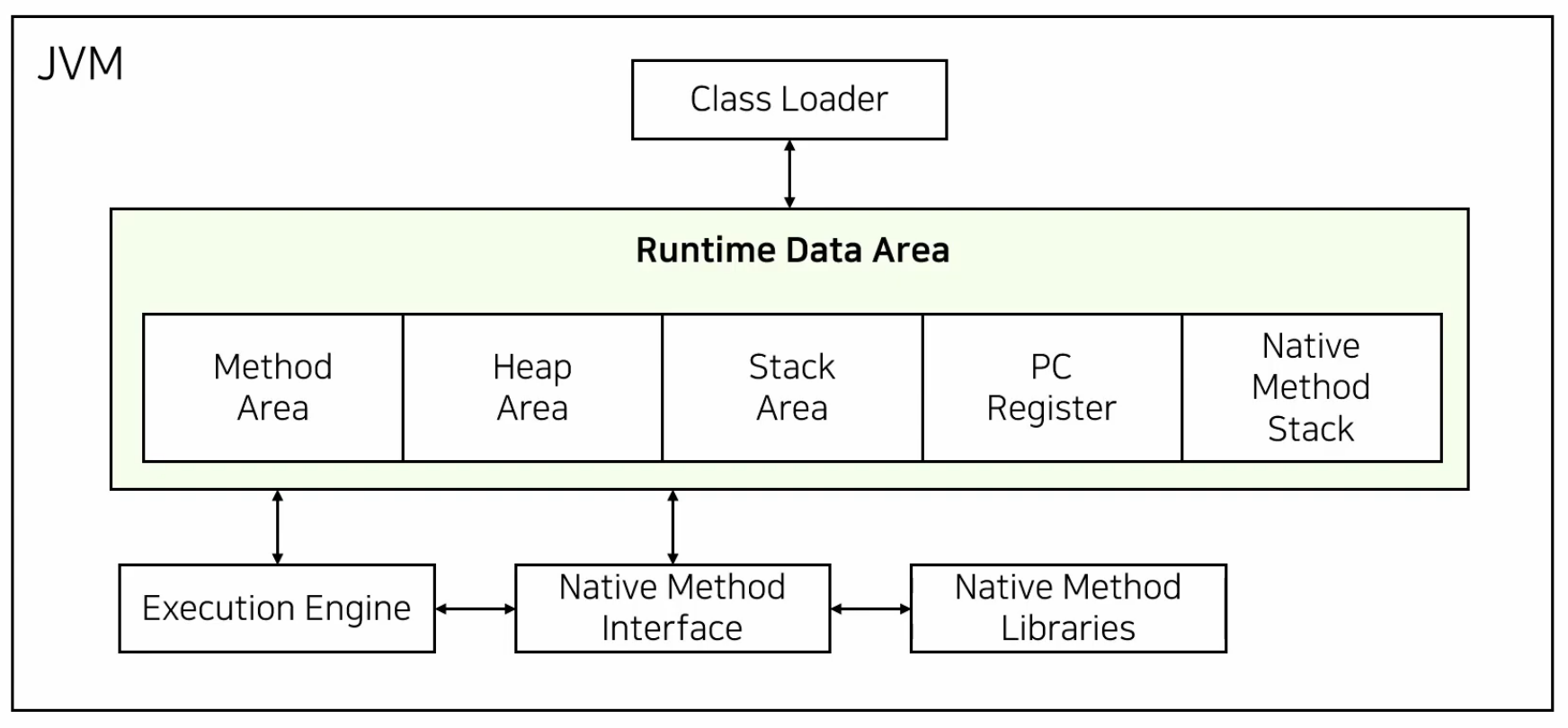
Class Loader
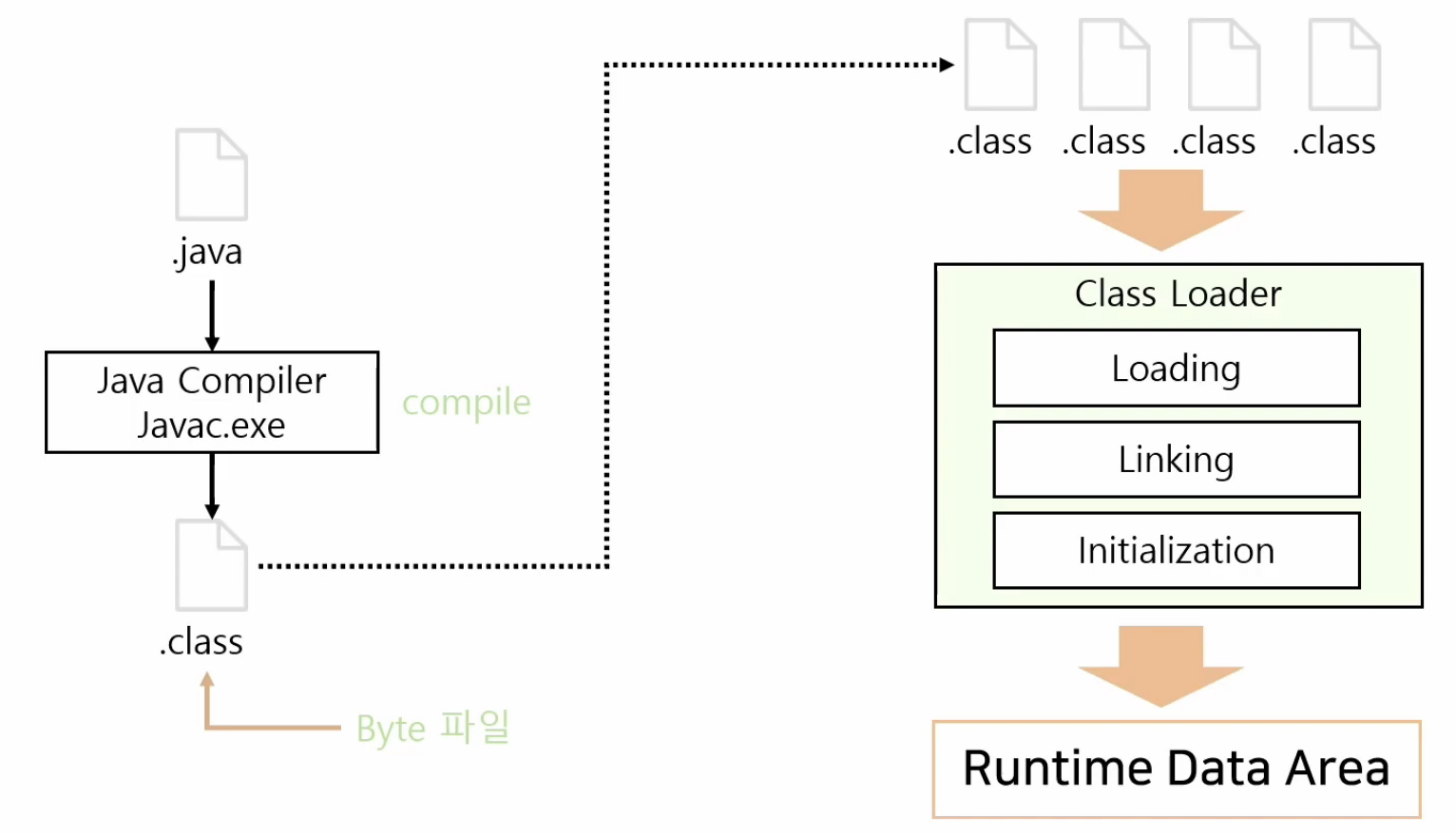
앱 실행 시 JVM은 메모리를 할당 받는다. 이 때 컴파일된 바이트 코드가 JVM의 Class Loader에 의해 3단계 과정(Loading Linking Initialization) 후 로드된 바이트 코드를 엮어서 JVM의 메모리 영역인 Runtime Data Area에 배치 한다. JVM의 Class Loader의 바이트 코드 로드 과정은 앱에서 호출 될 때마다 동적으로 메모리에 적재한다.
Execution Engine
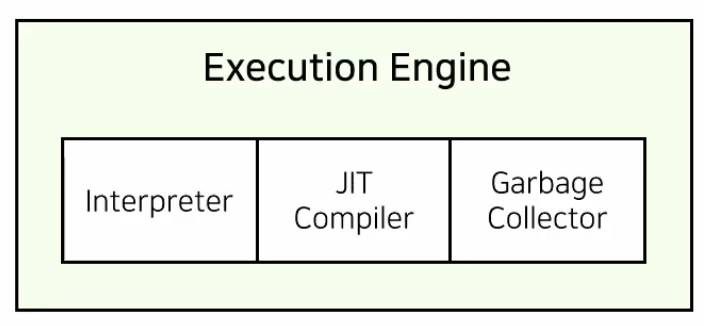
Run Time Data Area에 올라온 바이트 코드를 실행시키는 주체이다. 코드를 실행키는 방식에 크게 2가지가 존재한다. 인터프리터와 JIT 컴파일러이다.
Interpreter
바이트 코드를 해석하여 실행한다. 같은 메소드라도 여러번 호출 될 경우 그 때마다 해석하여 실행한다.
JIT Compiler
인터프리터의 단점을 해소하였다. 반복되는 코드를 발견하여 컴파일 후 Native Code(C, C++, 어셈블리어)로 변경하여 컴파일한다.
Garbage Collector
참조되지 않는 메모리 객체를 모아 제거하는 역할을 수행한다. 보통 자동으로 수행되나 수동으로 설정할 수도 있다. 수동 설정 시 실행이 보장되지 않는다.
Runtime Data Area
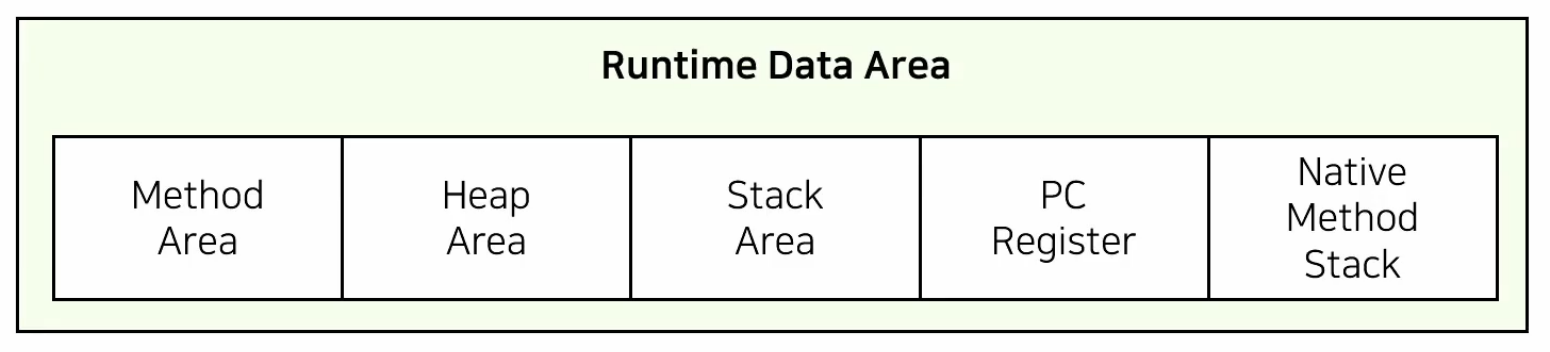
OS에 의해 메모리를 할당 받는 부분. 해석된 바이트 코드를 Runtime Data Area로 옮겨서 실행한다.
Method Area
JVM마다 단 하나의 Method Area 존재
Thread 간 공유되는 메모리
가비지 컬렉터 대상
저장
Runtime Constant Pool :: 상수 저료형 저장
Field Data :: 클래스 내 멤버 변수(데이터 타입, 접근 제어자, 변수 이름)
Method Data :: 메소드 이름, 리턴 타입, 매개변수, 접근 제어자
Method Code
Constructor Code
*Heap Area(Java 8)
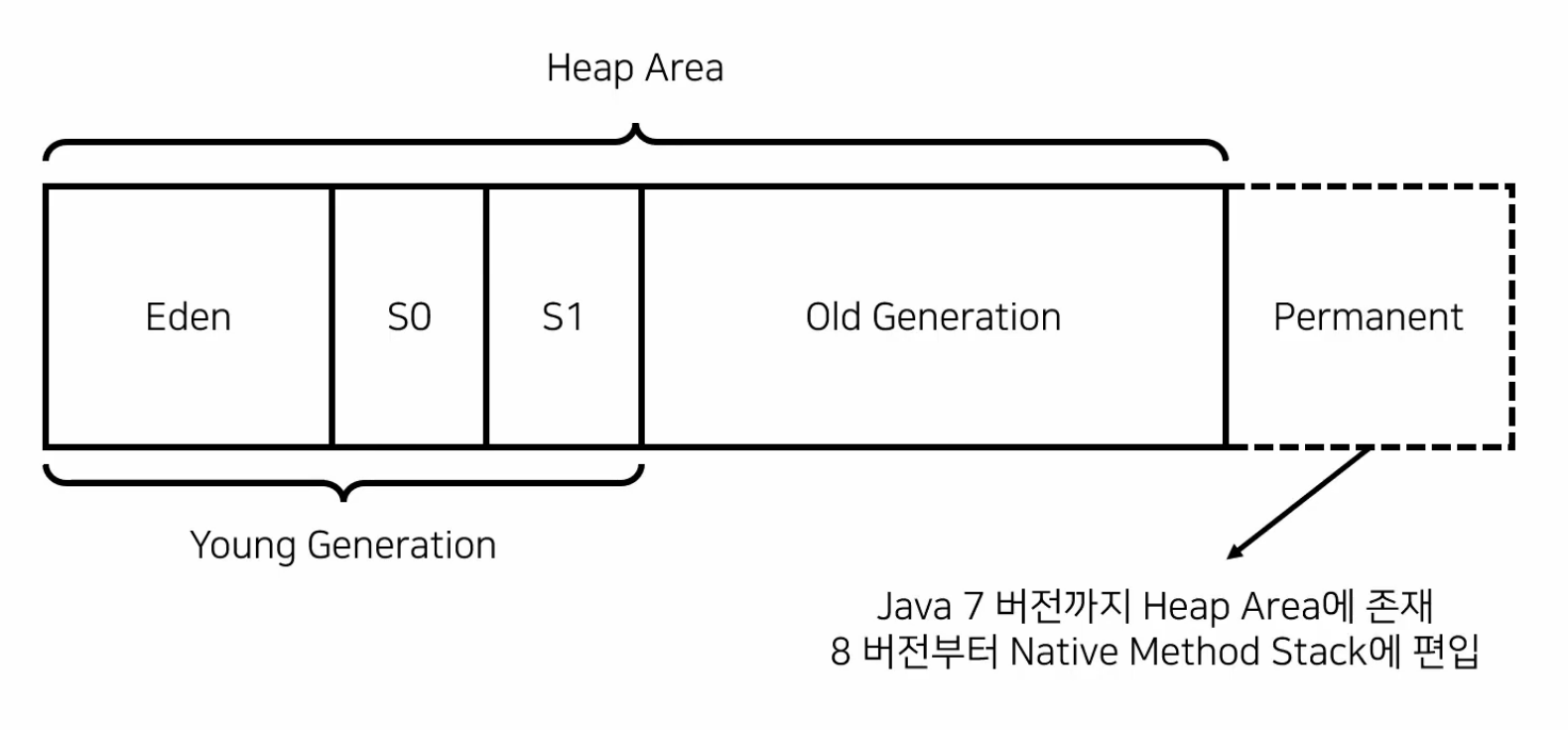
객체를 저장하기 위한 메모리
Thread 간 공유되는 메모리
GC의 대상
new 연산자로 생성된 모든 객체와 인스턴스 변수 그리고 배열을 해당 영역에 저장
Young Generation
생명주기가 짧은 객체. Eden에 할당 후 Survivor0과 Survivor1을 거쳐서 오래 사용된 객체를 Old Generation으로 이동시킴
Old Generation
생명주기가 긴 객체를 GC 대상으로 하는 영역
Garbage Collection 생명 주기에 의해 지속적으로 메모리가 정리됨
Minor GC
Minor GC의 대상이 되는 메모리 영역은 Young Generation 이다. 더이상 참조되지 않는 생애주기가 짧은 객체들이 GC의 대상이다.
Major GC
Major GC의 대상이 되는 메모리 영역은 Old Generation 이다. 더이상 참조되지 않는 생애주기가 긴 객체들이 GC의 대상이다.
Minor GC 와 Major GC의 차이점
GC의 대상이 되는 메모리 영역이 서로 상이하다. GC의 시간이 Minor GC의 경우 Major GC와 비교했을 때 상대적으로 짧다.
Stack Area
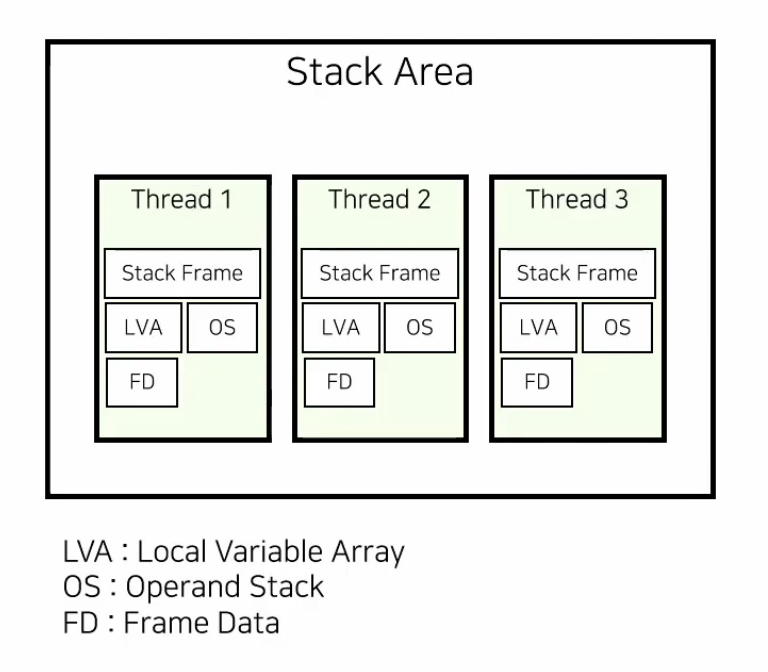
메소드를 호출 할 때마다 Thread 별로 함수 단위(Frame)로 쌓인다. 이때 데이터구조는 스택(LIFO)을 사용한다. 함수가 종료되면 스택에서 pop된다. 쓰레드 별로 할당받기 때문에 여러 쓰레드가 동시에 실행될 수 있다.
Stack Frame
함수의 지역변수, 함수의 매개변수, 프로그램 카운터(실행 할 명령어의 주소),이전 Stack Frame 주소 등의 정보를 담고 있다.
LVA(Local Variable Array)
Stack Frame의 일부분. 현재 메소드에 대한 지역변수와 매개변수 값을 담는다.
OS(Operand Stack)
함수의 결과값을 저장하는 임시 공간이다.
FD(Frame Data)
Stack Frame에 저장되는 모든 값들을 통틀어서 부르는 용어이다.
PC(Program Counter) Register

Thread가 시작될 때 생성. 쓰레드 마다 하나씩 존재한다. 현재 실행중인 상태 정보를 저장한다. 처리해야 하는 명령어를 처리하면 값을 증가시켜 그 값에 해당하는 명령어를 처리한다.
Native Method Stack
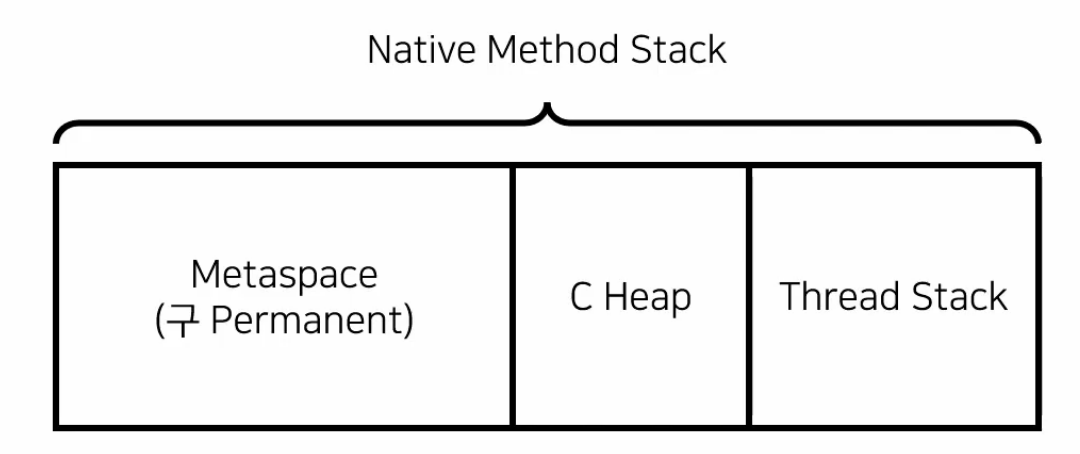
바이트 코드가 아닌 실제 실행할 수 있는 기계어로 작성된 프로그램을 실행시키는 영역이다. Java가 아닌 다른 언어로 작성된 코드를 처리하기 위한 영역이다. Java Native interface를 통해 바이트코드로 전환하여 저장한다. 각 쓰레드 별로 생성된다.
Java Native Interface

GC에 대해 설명해주세요
Garbage Collector
앞으로 사용되지 않을 객체의 메모리를 Garbage라고 한다. 이런 Garbage를 정해진 스케줄에 의해 정리하는 것을 Garbage Collection이라고 한다. 어플리케이션에 동적으로 할당한 메모리 중 더이상 사용하지 않는 영역을 정리하는 기능을 수행한다. 타겟은 Heap 영역이다.
STW(Stop The World)
GC를 수행하기 위해 JVM이 멈추는 현상을 의미한다. GC가 작동하는 동한 GC 관련 Thread를 제외한 나머지 모든 Thread는 멈춘다. 통상 JVM이 멈추는 시간을 단축하는 것을 튜닝이라고 한다. 튜닝을 이해하기 위해서 GC가 어떤 방식으로 어떤 경우에 발생하는지 학습 후 어플리케이션에 설정값을 넣어야 한다.
GC의 종류와 대표적인 알고리즘
GC에는 여러 종류가 있고 종류별로 사용되는 알고리즘이 다양하다.
Serial GC
하나의 CPU로 YG와 OG를 연속적으로 처리한다. 가장 오래됐으며 Mark-and-Compact 알고리즘을 사용한다. GC가 수행될 때 STW가 발생한다.
Parallel GC (JAVA 7, 8)
JAVA 7, JAVA 8의 기본 GC. CPU의 GC동안의 대기 시간을 최소화 하는 것을 목표로 만들어졌다. 대기 시간을 최소화 하기 위해 GC작업을 병렬로 처리한다. STW 시간이 짧아진다.
Parallel Compacting GC
Parallel GC에서 Old Generation 처리 알고리즘에 변화가 생긴 GC이다.
- CMS GC(Concurrent Mark-Sweep) GC
대표적으로 사용되는 GC이다. 앱의 Thread 와 GC의 Thread가 동시에 실행되어 STW를 최소화 하는 GC. Parallel Compacting CG와 구분되는 점은 Compaction 작업의 유무이다. CMS GC는 Compaction 과정을 수행하지 않는다.
- G1(Garbage First) GC
대표적으로 사용되는 GC이다. 큰 메모리에서 사용하기 적합한 GC. 대규모 Heap 사이즈에서 짧은 GC를 보장하는데 목적이 있다. 전체 Heap 영역을 Region 영역으로 분할하여 상황에 따라 역할을 동적으로 부여하는 특징이 있다. 필요에 따라 Eden, S1, S2를 설정하여 GC를 처리한다.
- Z GC
Z page라는 영역을 사용한다. G1 GC의 region은 크기가 고정인데 반해 Z page는 동적으로 운영된다. 정지 시간이 10ms을 초과하여 운영되지 않도록 목표로 한다. Heap 크기가 증가하더라도 정지 시간이 증가하지 않는 것이 특징이다.
GC Algorithm
Reference Counting Algorithm
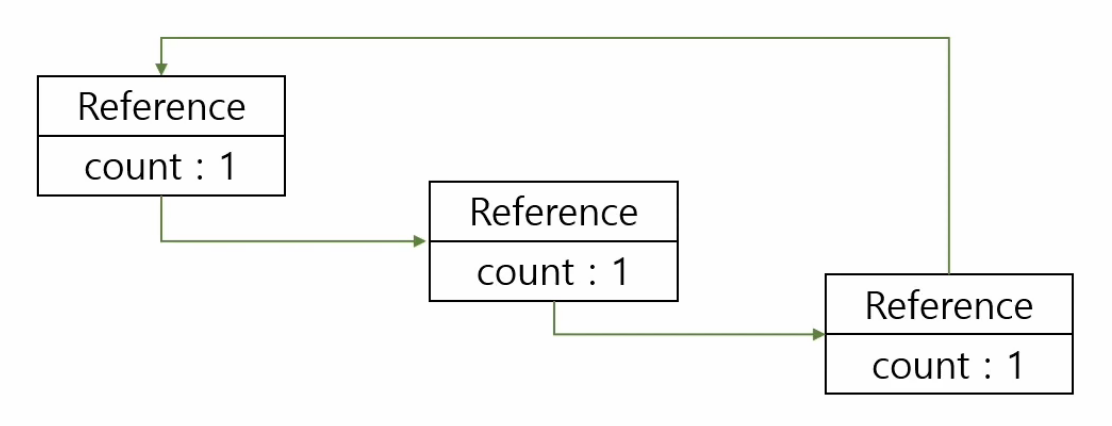
각 객체마다 Reference Count를 관리하며 이 카운트가 0이되면 GC를 수행한다. 카운트가 0이되면 바로 메모리에서 제거되는 특징이 있지만 순환 참조에서 Reference Count가 0이 되지 않는 문제가 발생하여 메모리 누수가 발생할 수 있다.
Mark-and-Sweep-Algorithm
위 알고리즘의 단점을 극복하기 위해 나온 알고리즘이다. RootSet(RSet)에서 부터 참조 상황을 파악한다. 여기서 RootSet은 위의 도식에서 가장 먼저 선언된 객체(왼쪽)로 볼 수 있다. Mark 단계에서 GC의 대상이 아닌 객체를 표시한다. Sweep 단계에서 마킹되지 않은 객체를삭제한다. Mark-Sweep 후에는 초기화한 후 다시 위 과정을 반복한다. Mark 작업과 앱내 Thread의 충돌을 방지하기 위해 GC과정 에서 Heap에 접근 할 수 없다.
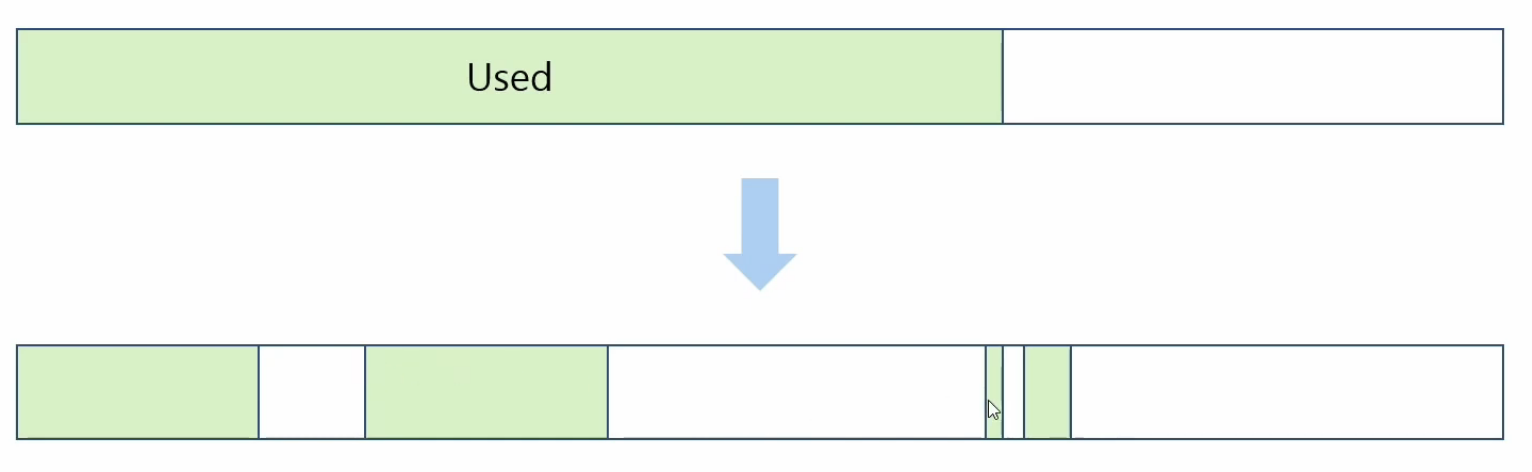
참조되지 않은 영역(마크되지 않은 영역)을 초기화 할경우 흰색으로 표시되는데 해당 공간 보다 큰 객체를 할당 하게 될 경우 메모리 부족 현상이 발생할 수 있는 단점이 있다. Mark-and-Sweep-Algorithm의 단점을 보완해서 나온 것이 아래 알고리즘이다.
Mark-and-Compact-Algorithm

Mark-and-Sweep-Algorithm의 단점을 보완한 알고리즘이다. 위 알고리즘의 경우 참조하지 않은 객체를 제거한 상태에서 멈추었지만 위 알고리즘의 경우 객체 제거 후 사용한 메모리를 모으는 과정을 통해 Heap 메모리를 사용한 공간과 사용하지 않은 공간을 분리하여 정리하는 작업을 수행한다. 하지만 이러한 Compaction 작업과 Reference Update과정에 대한 추가 비용이 발생한다.
Generational-Algorithm(일반적인 GC)
객체 생성시 Eden 영역에 생성. Minor GC가 발생하면서 사용 중인 객체는 Survivor1, Survivor2로 이동. 객체의 크기가 S1, S2보다 클 경우 Old Generation으로 이동. Survivor1과 Survivor2 영역 중 한 곳은 비워 주어야 하며 한 곳에만 객체가 존재해야 하는 규칙이 존재한다. 객체가 존재하는 공간을 From 객체가 존재하지 않은 공간을 To라고 한다.